Pulumiでプログラマのための「Infrastructure as Code」を実践する

「Infrastructure as Code (IaC)」という言葉が生まれてからしばらく経ちました。IaCは簡単に言えばインフラをコード化するという概念です。この言葉に触れた当時はインフラをプログラミングできる時代がやってくるのだと思い、プログラマとして非常に心が躍りました。しかし残念ながらその気持ちは長くは続きませんでした。Ansible, Chef, Puppet, CloudFormation, AWS SDK, Terraform・・・ これらの技術はどれも素晴らしいものだと思います。Docker Composeやkubectl applyには感動した記憶もあります。しかしプログラマとしての自分が告げるのです。何かが足りない・・・本当に欲しいのは「コレジャナイ」と。そして長い、長い旅路の末にようやく巡り会うことができました。Pulumiという希望の星に。
はじめに
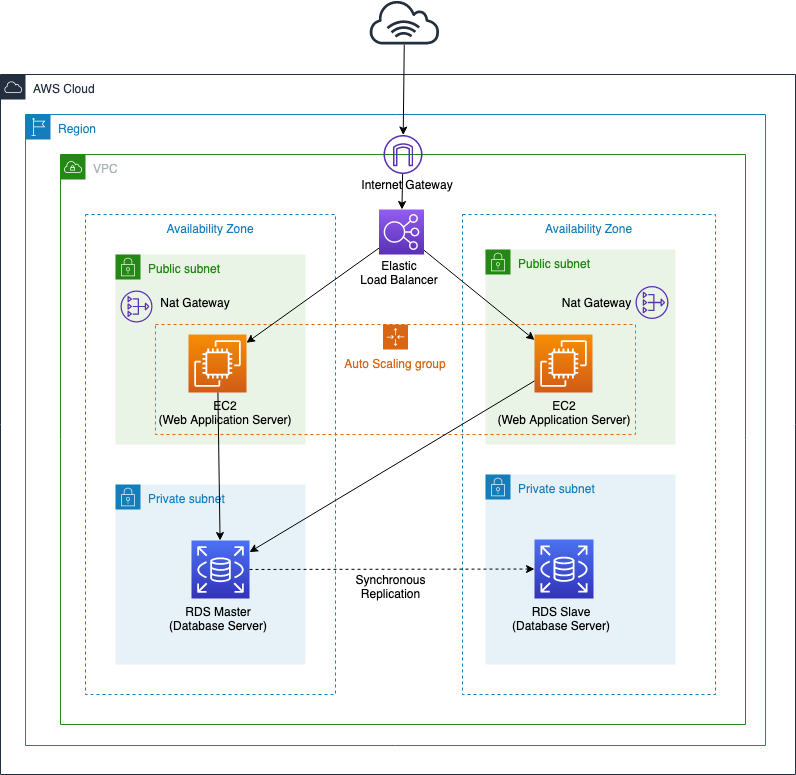
本記事ではPulumi[^1]で「Infrastructure as Code」を実践します。具体的にはAWS上に以下の2層構造のWebアプリケーション^2のインフラを100行未満のTypeScriptで記述します。
[^1]: PulumiはモダンなInfrastructure as Codeを実践するためのプロダクトであり、OSSです。そして、それを開発、サポートする会社の名前でもあります。Pulumiの由来はハワイ語の箒(ほうき)になります。もしくはPulumiの創業者でありCEOでもあるJoe Duffyの親友でもあった「Chris Brumme(故人)」の名前の誤発音です。詳細はJoe Duffy's Blogを参照してください。
実践 Infrastructure as Code
Pulumiではインフラの状態が内部で管理されているので、インフラを簡単に作ったり、壊したりすることができます。また、今回は静的型付き言語であるTypeScriptを選択したので、インフラの「型」を簡単に確認でき、IDEのサポートが受けやすいです。そしてTypeScriptは汎用言語でもあるのでインフラを関数やライブラリ化したり、インフラをループで大量に生成するのも簡単です。まさにプログラミング感覚でインフラが構築できて、いらなくなったら簡単に破棄できるのでプログラマのためのIaCを実践するのにPulumiはうってつけです。
Pulumiの導入
PulumiのGet Startedに従って、Pulumi CLI、AWS CLI、Node.jsをインストールしてください。
(「Configure AWS」まで進めてください。)
pulumiログイン
以下のコマンドでpulumiにログインしてください。
1 | |
ブラウザでログインする場合は上記のコマンド後に「Enter」キーを押します。するとブラウザ側でサインインできます。自分はGitHubでPulumiにサインインしましたが、他にもGitLabやE-mail等でもサインインできます^3。
プロジェクトとスタックの作成
次にプロジェクトとスタックの作成をします。以下のコマンドで実行します。
1 | |
pulumi newは基本的にはデフォルトでOKなのでEnterで進めますが以下の質問だけ「ap-northeast-1」にしてEnterを押してください。
aws:region: The AWS region to deploy into: (us-east-1)
index.tsの作成
メインファイルであるindex.tsファイルに以下を記述してください。
1 | |
utils.tsの作成
同じフォルダにutils.tsを作成して、ファイルに以下を記述してください。コーディングは以上です。
1 | |
これで見事に冒頭で示した構成がindex.tsとutils.tsを合わせて100行弱のコードで作成できました。
インフラのデプロイ
以下を実行してください。途中で本当に実行してよいか聞かれるので「yes」を選択してEnterを押してください。インフラの作成には数分かかります。
1 | |
デプロイ結果の確認
pulumi upが成功すると最後の出力結果にendpointが表示されるので、そのURLにブラウザからアクセスしてみてください。
「Hello, World! from ap-northeast-1a」が表示されたら成功です。ロードバランサを挟んでいるのでリロードでするごとにAZの部分(from ap-northeast-1a)が変わります。また実際にAWSのコンソールにログインしてEC2やRDSやVPCの構成も確認してみてください^4。
リソースの後片付け
確認が終わったら以下のコマンドでリソースを破棄してください。リソースの破棄をしないとAWSの料金が発生し続けるので不要になったらすぐに破棄するようにしてください^5。
1 | |
コードの解説
短いのであまり解説する必要もないかもしれませんが、index.tsだけ一応簡単にコメントします。魔法はライブラリの「awsx」にあります。これは「Pulumi Crosswalk for AWS」というライブラリで、AWSのwell-architectedなベストプラクティスを実装しています。以下のコードでは「new awsx.ec2.Vpc(vpcPrefix)」が凄い仕事をしていて、二つのパブリックサブネットと二つのプライベートサブネットとインターネットゲートウェイ、NATゲートウェイやそれに付随するセキュリティグループなど様々なものを生成しています。それ以外はAWSの知識があれば割合素直に読めるのではないかと思います。
1 | |
util.tsも含めた全体の処理の流れは以下のとおりです。
- VPCの作成
- VPCの作成
- 2つのパブリックサブネットの作成
- NATゲートウェイの作成
- 2つのプライベートサブネットの作成
- NATゲートウェイの作成
- インターネットゲートウェイの作成
- 必要なルートテーブルやセキュリティグループの作成
- RDSインスタンスを作成
- セキュリティグループの作成
- ふたつのプライベートサブネットを対象にサブネットグループの作成
- サブネットグループにRDSインスタンスの生成
- アプリケーションロードバランサの作成
- セキュリティグループの作成
- アプリケーションロードバランサの生成
- ターゲットグループの作成
- ロードバランサ用のターゲットグループを作成
- リスナーを作成
- ロードバランサ用のリスナーを作成し、転送先に上記で作成したターゲットグループを設定
- オートスケーリンググループの作成
- 起動設定の作成
- 最新のAmazonLinuxを検索してAMIのIDを取得
- 起動設定のユーザデータとして起動コマンドを渡してpythonの
SimpleHttpServerが立ち上がるようにする
- パブリックサブネットとロードバランサを指定してオートスケーリンググループの生成
- オートスケーリングは2から4インスタンスの幅に設定
- スケーリングポリシーの設定
- CPU使用率が50%を基準にスケーリングするように設定
- “endpoint”の出力
注意すべきは、実際にPulumiが上記の流れどおりにリソースを作成しているわけではないということです。プログラマはあくまでリソースの依存関係だけを気にしてプログラムを作成すればよく、実際のリソースの作成はPulumiが依存関係を賢く判断して並列に作成できるリソースは並列に作成してくれます。 さらに言えば、Pulumiは上記のプログラムを「実行」して実際に必要なリソースを確定し、現在すでに存在するリソースとの差分を計算して差分のリソースだけをAWS側に作成してくれます。つまり一旦上記のコードをpulumi upで実行したあとにEC2インスタンスを作成するコードを付け足して再実行した場合には、差分であるEC2インスタンスの作成のみが行われるということです。これは例えるならPulumiはキャッシュ付きの自動並列化コンパイラのような役割を果たしていると考えられると思います。
一番最後の「”endpoint”の出力」は分かりづらいかもしれませんが、変数をexportしておくとpulumi upした最後の結果として変数の値を出力してくれます。また「pulumi stack output <変数名>」を実行することで変数の値を出力することができるので、外部のプログラムとの連携が容易になります。
Pulumiのいいところ
Pulumiのいいところは以下のとおりです。
- マルチクラウド
- AWS
- Azure
- Google Cloud Platform
- Kubernetes
- OpenStack
- 複数の汎用言語をサポート
- Node.js - JavaScript, TypeScriptやその他のNode.js互換言語(JSに変換可能)
- Python 3 - Python 3.6 or greater
- Go(PREVIEW)
- インフラのリソースの状態を管理している
pulumi upしたとき前回実行時からの差分のリソースだけを作成するpulumi destroyで作成済みのリソースを破棄する
- 複数のプロジェクト、スタックを使い分けられる
- スタックごとに変数を定義できる
- Secretの管理もできる
1つ目はマルチクラウドなところです。AWSやAzureやGCPのようなパブリッククラウドだけではなくOpenStackもサポートしています。またKubernetesのようなコンテナオーケストレーションもPulumiでコード化することができるので、Pulumiを覚えるだけで非常に広範囲のインフラ構築を自動化できることが分かると思います。
2つ目は複数の汎用言語をサポートしていることです。現在はJavaScriptやTypeScriptやPythonがサポートされており、Go言語も仲間入りする予定です。また拡張可能なように作られていて自分のお気に入りの言語を追加することも可能です^6。
3つ目はインフラのリソースの状態をPulumi側で管理していることです。このことでプログラマは最終的にあるべき状態だけを意識するだけでインフラをプログラミングできます。もしこれが現在のリソース作成状況を意識しながらプログラムを考えなければ行けないとすると非常に大変です。インフラの最終状態だけを思い浮かべてロジックに集中できるということはプログラマにとってありがたいことです。
もう一つプログラマに取ってありがたいのはリソースの削除がpulumi destroyで簡単にできることです。プログラマは基本的にはトライアル&エラーでプログラムを作成することに慣れています。しかしリソースの破棄が面倒であれば試行錯誤する気にもならないかもしれません。実際のインフラではリソースに複雑な依存関係がついており順番を守らなければリソースの削除に失敗することもよくあります。しかし、Pulumiはリソースの状態を管理して、依存関係を把握することで、大量かつ複雑な依存関係のリソース群を一括で削除できます。
4つ目は複数のプロジェクトおよびスタックを使い分けられることです。プロジェクトは再利用の単位にもなっていて「自分が作成したインフラ」を簡単に公開して共有することができます。今回作成したコードも以下にGitHubで公開してあるので、ぜひ試してみてください。
👇 hinastory/aws-ts-two-tier-web: 2-tier web application hosting example for AWS by Pulumi

また、プロジェクトの中でスタックを作成でき、コードの中で利用可能な「設定」を定義できます。例えばリージョン情報やユーザ名やパスワード等を「設定」としてコードから外出しすれば再利用性が高まり、スタックの切り替えで「設定」の切り替えもできるので非常に便利です。一番よくある使い方は開発用のスタックと本番用のスタックを分けるやり方です。その他にもパスワードを暗号化して管理する方法も提供されているので安全にインフラを共有することが可能です。
Pulumiの仕組み
Pulumiの仕組みは以下のとおりです。
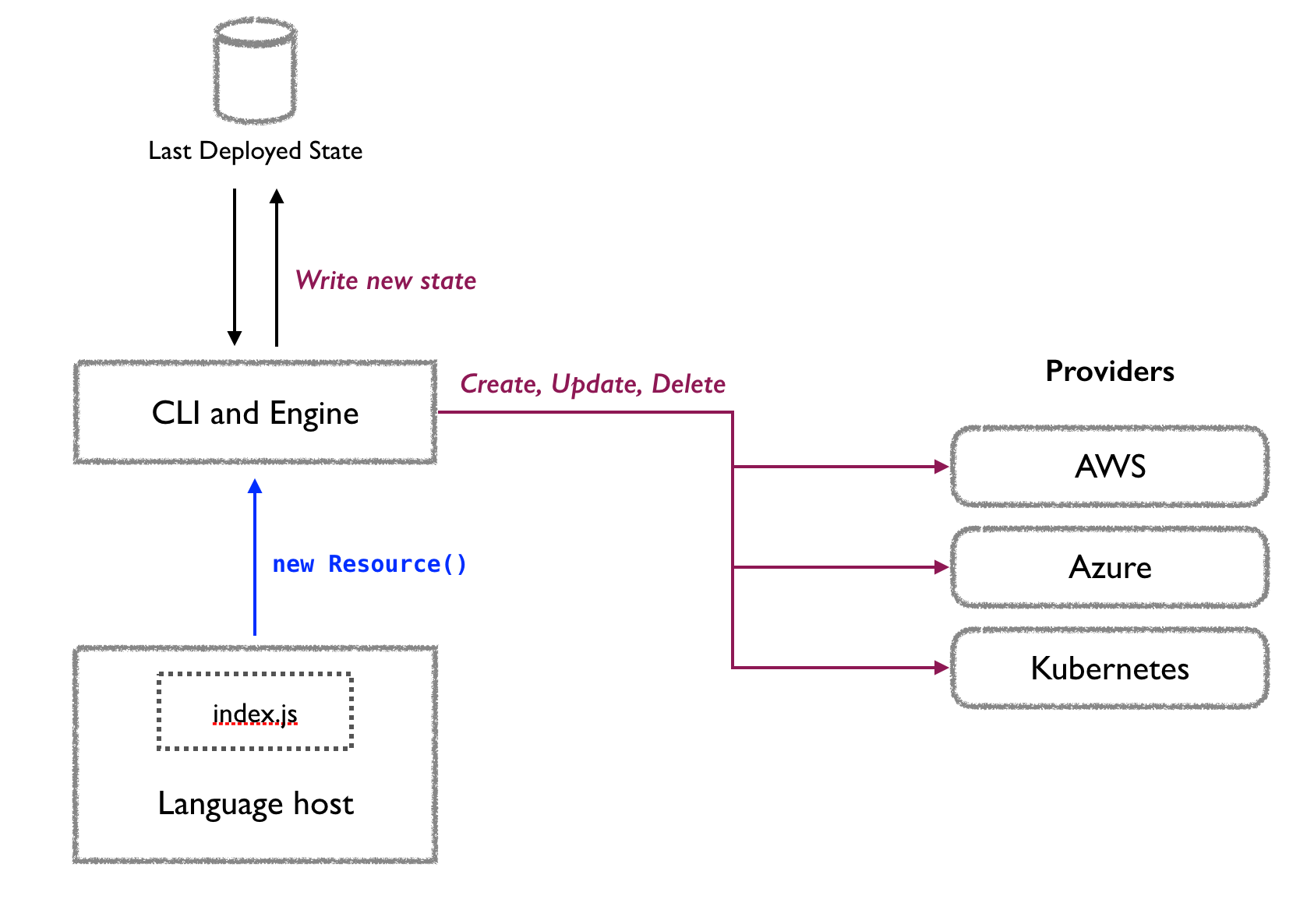
How Pulumi Worksより引用
まず言語ホストがTypeScript等のコードを実行して、その結果をPulumiのエンジンに伝えます。Pulumiのエンジンは最後のデプロイの情報を確認して、必要に応じてクラウド上のリソースの作成、更新、削除を行い、その結果をまたデプロイの最終結果として保存します。最終結果の保存先はデフォルトでは Pulumiのサービスになりますが、ローカルやクラウドストレージ上に保存することも可能です。
まとめ
本記事ではPulumiを利用して100行未満のTypeScriptでAWS上に高可用な2層構造のWebアプリケーションのインフラを作成しました。Pulumiを利用した利点は以下のとおりであり、プログラマが「Infrastracture as Code」を実践するのに最適なツールだと感じました[^7]。
- マルチクラウド
- AWS, Azure, GCP, OpenStack, Kubernetes
- 汎用言語で記述できる
- 汎用言語の表現力や生産性を享受できる
- JSONやYAMLやその他DSLだと関数やロジックを記述する上での制約が大きく、少し複雑なことをしようとすると生産性が激減してプログラマの力を活かしきれない
- TypeScript等の静的型付け言語ではさらに型情報もあるので、IDE(VSCode等)から補完や定義の確認等のサポートを受けられる
- 汎用言語の表現力や生産性を享受できる
- 状態を管理している
- リソースの差分だけを自動で更新してくれる
- リソースの依存関係を理解して並列でリソースの作成をするので処理が速い
- リソースの状態や依存関係を理解しているので関連リソースの安全な削除が可能
- インフラのコードの再利用性のための枠組みがある
- 今回作成したコードは aws-ts-two-tier-web - GitHubで公開中
自分はずっとインフラに苦手意識を感じていました。その理由は失敗したら簡単には元に戻せないことと、物理的な制約により抽象化が難しいからです。プログラマとしての自分はこれらの理由によりずっとインフラは苦手なままだと思っていました。クラウドが現れて、多くが仮想化されてもまだ抽象化に難があり状態管理が面倒だと感じていました。しかし時は流れてようやくインフラに抱いていたコンプレックスが解消されつつあります。
汎用言語の表現力と生産性を身につけ、主要な「インフラ」をカバーし、インフラの煩わしい状態管理からの解放を告げたPulumiの出現により、プログラマのためのIaCがようやく登場したことを確信したのです。
もはやインフラが「ハード」と思われる時代は過ぎ去り、プログラマが柔軟に抽象化し、ライブラリ化し、複雑なインフラ構成をも再利用可能にしていく時代が到来しようとしています。そしてPulumiはその先頭を走るプロダクトであり、自分は多くのPulumiプロジェクトがネット上に公開され、多くのインフラコードのエコシステムが生まれてくることを願って止みません。
本記事がPulumiの普及とプログラマのためのIaCの一助になれば幸いです。
[^7]: Pulumiが他のIaCツールと何が違うのかを詳しく知りたい方は「Pulumi vs. Other Solutions」を参照してください。
参考文献
- Pulumi Documentation
- Joe Duffy - Hello, Pulumi!
- Pulumi Advances DevOps on AWS - DevOps.com
- Pulumi Crosswalk Aims to Simplify Deploying to AWS - The New Stack
- Infrastructure as Code: Chef, Ansible, Puppet, or Terraform? | IBM
- Infrastructure as Code - Wikipedia
- 私は Infrastructure as Code をわかっていなかった - メソッド屋のブログ
- まだTerraform使ってるの?未来はPulumiだよ | apps-gcp.com
- Terraform と Pulumiを比較する | apps-gcp.com
- これが次世代プロビジョニングツールの実力か!? PulumiでAWSリソースを作成してみた | DevelopersIO
- Pulumi で AWS Application Load Balancer を構築する - Qiita
- 昨今話題?の Pulumi を使ってみた - Qiita
- pulumiのチュートリアルをやってみた - Qiita
- pulumiのapplyを理解する - Qiita
- Pulumiの状態管理にクラウドストレージバックエンドを使う - Qiita
- Pulumi+VSCodeの書き心地が抜群な件 - Qiita
- PulumiのProviderをTerraformのProviderから実際に作成してみた - Qiita