Re:FizzBuzzから始めるRust生活

新しいプログラミング言語に入門するためには、やはり手を動かすことが大事です。本を読んで体系的に学ぶのももちろん重要ですが、それは言語の魅力を知ってからでも遅くはありません。
しかし「Hello World」レベルだと簡単すぎて言語の違いを味わえず、ネットワークプログラミングのような高度なプログラミングはフレームワークの力が大きすぎて言語とフレームワークの狭間で立ち往生することになります。
そこで登場するのが「FizzBuzz」です。「FizzBuzz」は単純なプログラムでありながら、プログラムの真髄である「順次」、「分岐」、「繰り返し」があり、数値計算も学べる興味深い題材です。
その「FizzBuzz」を利用して「Rust」という言語を学んでみようのが本記事の趣旨です。「FizzBuzz」というシンプルなプログラムで「Rust」のような表現力が豊かな言語の機能をどこまで使い尽くせるのかは興味が尽きないところですが、本記事では入門という観点で初歩的なFIzzBuzzから順を追って体を慣らしながらRustのある生活を体験できるようにしたいと思います。
さぁ、FizzBuzzからRust生活を始めましょう。
はじめに
本記事は、すでに何らかのプログラミング言語の経験を持っているRust初心者を対象としています。特になんとなく「Rust怖い」感じている方に対して、Rustの普段使いの魅力をFizzBuzzのようなシンプルな題材を通してお伝えできればと思います。
前提知識
まずは前提知識としてFizzBuzzプログラムとRust言語の特徴を簡単に説明します。すでにご存知の方はこの節は飛ばして頂いても構いません。
FizzBuzzプログラムとは
FizzBuzzプログラムは、3で割り切れる場合に「Fizz」と表示し、5で割り切れる場合に「Buzz」と表示し、両者で割り切れる(15で割り切れる)場合には「FizzBuzz」と表示するプログラムです。1から16の数値の入力に対する出力は以下のようになります。
1 | |
本記事では1から100までの数字を上記のルールで変換して画面に出力するFizzBuzzプログラムを扱います。
Rustとは
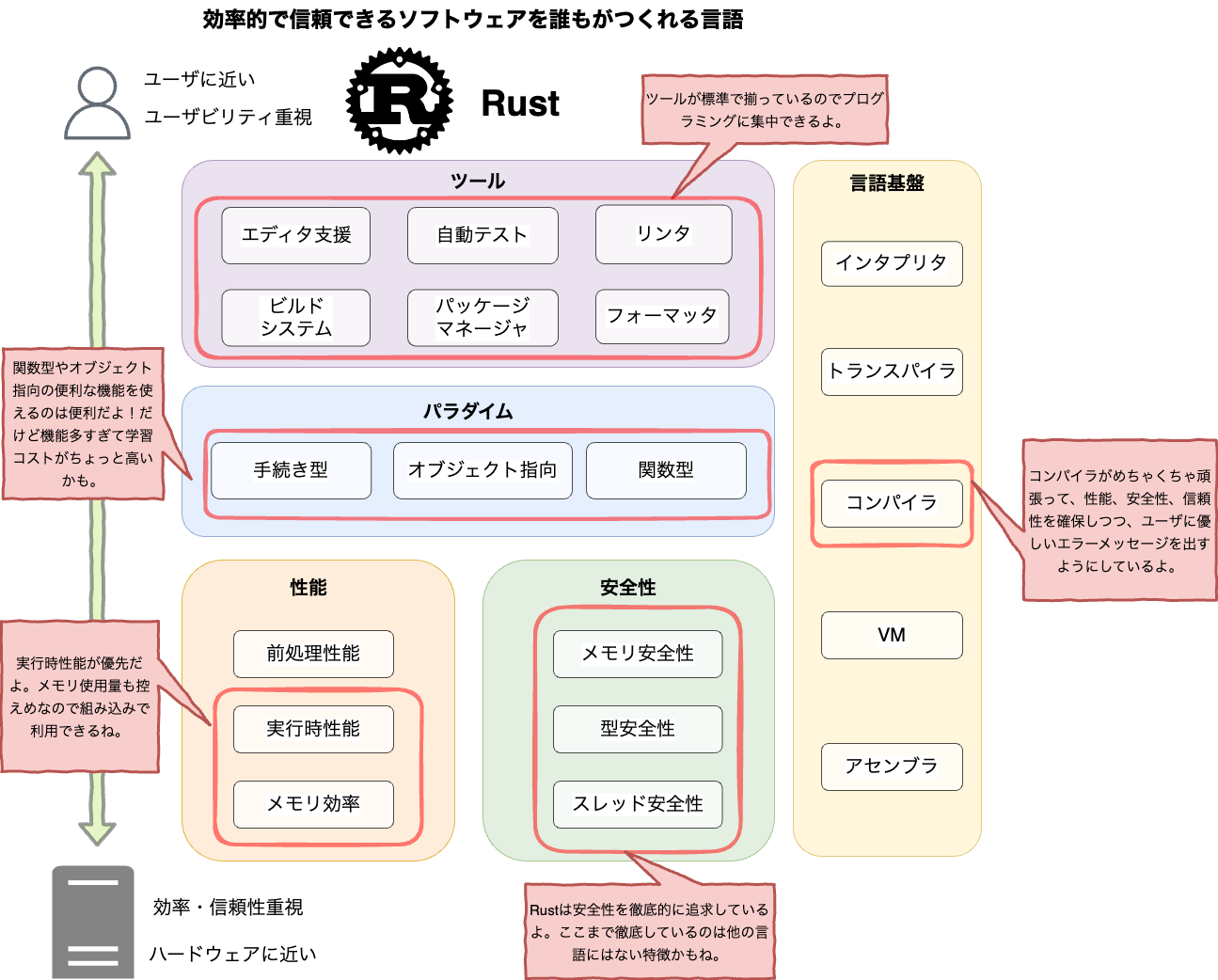
RustはMozilla^1が支援するオープンソースのプログラミング言語です。Rust公式サイトから引用すると以下の3つの特徴があります。
- パフォーマンス
- Rustは非常に高速でメモリ効率が高くランタイムやガベージコレクタがないため、パフォーマンス重視のサービスを実装できますし、組込み機器上で実行したり他の言語との調和も簡単にできます。
- 信頼性
- Rustの豊かな型システムと所有権モデルによりメモリ安全性とスレッド安全性が保証されます。さらに様々な種類のバグをコンパイル時に排除することが可能です。
- 生産性
- Rustには優れたドキュメント、有用なエラーメッセージを備えた使いやすいコンパイラ、および統合されたパッケージマネージャとビルドツール、多数のエディタに対応するスマートな自動補完と型検査機能、自動フォーマッタといった一流のツール群が数多く揃っています。
Rustを利用しているユーザにはMozillaはもちろんDropboxやAWSやMicrosoftなどの著名企業も含まれるので、今後も安定して開発やメンテナンスが行われる言語だと考えられます。
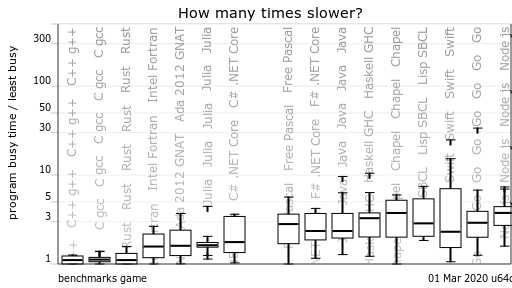
向いている用途としてはシステムプログラミングが挙げられ、OSやデータベース等のミドルウェアの開発に適しています。個人的にはC/C++やGo言語が向いている用途にはRustも適していると考えています。特に性能を要求されるプログラムには向いています。以下はComputer Language Benchmarks Gameからの引用ですが、Rustの性能がC/C++と同等であることが示されています。
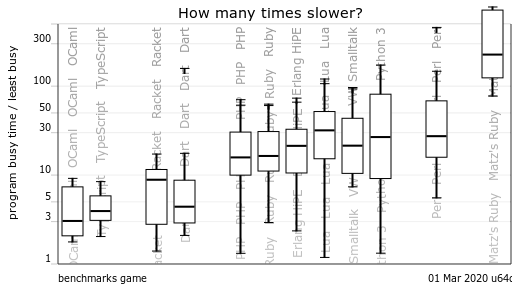
向いていない用途としては、RubyやPythonのようにプログラムを書いてすぐに実行するような軽量的な使い方です。Rustは必ずコンパイルする作業が発生し、しかもコンパイラのチェックが比較的厳しいので^2「正しい」プログラムを書くのに時間がかかります。これはある程度大きな開発時にはメリットともとれますが、アイデアをプログラムで緩く試したい場合には不向きなので用途で使い分ける必要があります。
第一章 Rust生活:初級編
さて、ここからが本題のRust生活です。1日にひとつのFizzBuzzを紹介するというスタイルで書いています。後半に行くほど難しくなっているので、自分のレベルに合った箇所から読み進めて頂いても構いません。
また、FizzBuzzプログラムのスタイルとしては関数として記述しています。実際にコンパイルして実行するには以下のようにmain関数の中から呼び出す必要があります。
1 | |
各ソースコードには「Run」のリンクが貼ってあるので具体的にはそのソースコードを見て実行してみるとより挙動が分かると思います。
1日目 〜FizzBuzzでwhileとifに再会する〜
まずは多くの方が理解できる形のFizzBuzzから始めたいと思います。以下のRustプログラムは多少文法が異なっていてもC/C++やJava等の手続き的なパラダイムを持つ言語を経験した方ならすんなりと読めると思います。
1 | |
まず、1行目はfnで始まる関数宣言です。fizz_buzz1という関数を定義しています。関数名はこのようにアンダースコア(_)で区切った小文字のスネークケースで書くのがRustのコーディング規約になっています。この関数は引数を持っていませんが戻り値は一応あります。戻り値はユニット()になります。ユニットは意味を持たない値の代表として用いられます。
2行目のletで始まる文は宣言文と呼ばれており、関数のスコープに変数xを導入して整数1に束縛しています。mutキーワードはmutableの略であり、この変数が再代入可能であることを示しています。再代入が可能になるとプログラムの挙動の把握が難しくなるので^3、不必要な箇所ではmutをつけないことがRustの基本です。
さらに、2行目は型推論により変数の型が省略されています。省略せずに書くと以下のようになります。
1 | |
「i32」は32ビットの符号付き整数を意味しています。またRustは静的型付言語なので全ての変数には「型」がついていますが、型推論のおかげて必要以上の型を記述せずにすみます。ちなみに再代入可能な変数であっても変数の型は変更できません。つまり以下のようになります。
1 | |
ちなみに以下のようにletを用いて同じ変数を再初期化してあげれば異なる型の数値への束縛が可能です。この機能はシャドーイングと呼ばれています^4。
1 | |
次にwhileとifですがこれの機能は他の言語と同等の機能をもっています。whileは条件付き繰り返しで、ifは条件分岐です。付け加えるとするならこれらは両方とも式であり、評価された値を持ちます。whileは必ずユニット()値を返します。ifは条件分岐の評価結果を返します。このあとで説明するprintln!(...)は全てユニット値を返すので、この関数内で使われているifもユニット値を返します。
次の要素は「println!」マクロです。関数っぽく見えますが名前の最後の「!」がマクロであることを示しています。Rustの関数には可変長引数がないのでマクロを使って実現されています^5。呼び出し側は呼び出し先が関数かマクロかはあまり気を使う必要がないので、入門の段階では気にしなくても問題はありません。println!マクロでは表示する文字列に変数を埋め込むことができます。「{}」はプレースホルダになっていて以下のように複数利用することもできます。
1 | |
1日目の最後の説明はx += 1についてです。この式は他の言語と同じくx = x + 1のシンタックスシュガーです。つまり再代入の処理になります。Rustでは再代入はmutをつけて宣言された変数にしか許可されませんが、xはmut付きで宣言されているのでこのように再代入が可能です。ちなみにRustにはインクリメント演算子(++)は用意されていません。
2日目 〜FizzBuzzでforとrangeに出会う〜
1日目のプログラムでFizzBuzzは問題なく動作します。しかし、whileの条件判定とx += 1を組み合わせてループを行うのは些か面倒です。でもご安心ください。Rustにはループの強い味方、forとレンジ(範囲)があります。
1 | |
for a in bの構文はbで「イテレータ」を受け取り、「イテレータ」が返す値を順番に直後のブロック内においてaという変数で利用可能にします。イテレータは .next() メソッドを繰り返し呼び出すことができ、その都度順番に値を返します。
a .. bはレンジであり、a以上b未満を表しています。上記のプログラムでは1 .. 101になっているので1以上101未満になります。「未満」なので終端の数字は含まないことに注意してください。終端を含めたい場合、つまりa以上b以下を表したい場合はa ..= bとします。レンジはイテレータにもなっているので、forで用いることができます。
3日目 〜FizzBuzzでmatchにときめく〜
2日目のプログラムでforを導入して大分いい感じになりましたが、まだ冗長な点が目に止まります。if式です。else ifを繰り返し書いているのでもう少し短く書きたいものです。そこで登場するのがmatchです。
1 | |
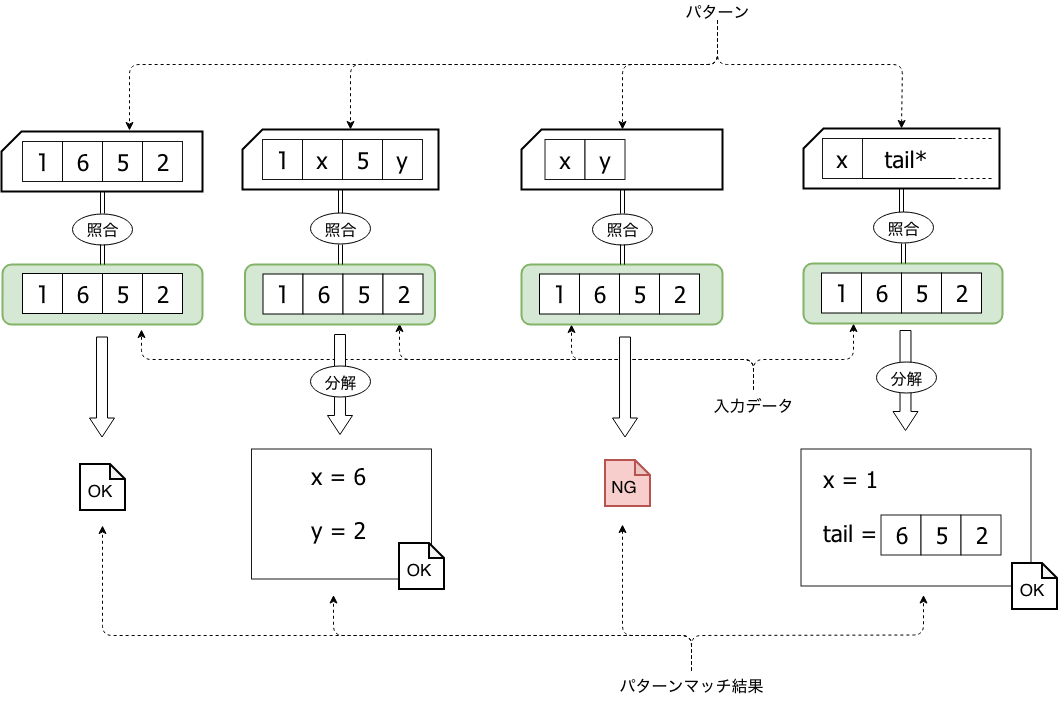
match a {b}の構文では、aの式を評価した結果をbのパターンで網羅的に分類できます。bのパターンはp => vの形式(これはアームとも呼ばれます)でカンマ,で区切って複数並べることができ、上から順番にpのパターンにマッチングするか検査されます。マッチングが成立するとvが実行されてその評価値がmatch式の評価値となります。
pのパターンでは一つの値だけではなく|で区切って、複数の値にマッチングさせることもできます。例えば上記でいけば3 | 6 | 9 | 12は「3または6または9または12」の意味になります。またパターンにアンダースコア_を用いるとワイルドカードパターンになり、全ての値にマッチングします。パターンは上のほうが優先順位が高いのでワイルドカードパターンは通常一番下に置かれます。
上記の例だけ見るとmatchは単にifのシンタックスシュガーのように見えてしまいますが、実は大きく異なります。そのひとつにmatchでは網羅性検査が行われる点があります。例えば以下のようにワイルドカードパターンを99に置き換えてコンパイルしてみます。
1 | |
するとコンパイルエラーになり、以下のように色付きでわかりやすくエラーが表示されます。

「non-exhaustive patterns」はパターンが網羅的でないというエラーです。パターンの網羅性はマッチング対象の型の値域を網羅しているかどうかで判断されます。この場合xはi32型で符号付き32ビット整数なので値域はstd::i32::MIN(−2,147,483,648)〜std::i32::MAX(2,147,483,647)になります。std::i32::MINとstd::i32::MINはRustで定義されている定数で符号付き32ビット整数の最小値と最大値を表しています。
「patterns std::i32::MIN..=-1i32, 1i32..=2i32, 4i32 and 3 more not covered」は、std::i32::MINから-1までと1から2までと4がカバーされておらず、さらに3つ以上カバーされていないものがあると言っています。このようにRustはエラーメッセージが丁寧で具体的にカバーできていない範囲をエラーメッセージが教えてくれます。
4日目 〜FizzBuzzでガードを覚える〜
3日目のプログラムでifをmatchでスマートに置き換えることに成功しました。しかし、また別の不満が出てきました。”3 | 6 | 9 | 12”のように3の倍数を列挙するのではなく、2日目のプログラムのように”x % 3 == 0”といた形で「余りが0」で3の倍数を表現したいのです。そこでパターンガードの出番です。
1 | |
上記のプログラムのe if e % 15 == 0においてeは変数パターンと呼ばれていて、任意の値にマッチして指定した変数を値に束縛します。変数名自体はeでなくても何でも構いませんが、アーム内でシャドーイングが起こることだけ注意してください。if e % 15 == 0がパターンガートよ呼ばれるもので、条件を満たす場合だけこのアームがマッチします。
パターンガードがない変数パターンはワイルドカードパターンと似ていて何にでもマッチするので、通常パターンの一番最後におこかれます。両者の違いは変数を束縛するか否かの違いだけです。
第二章 Rust生活:中級編
いよいよ中級編に突入です。ここからは少し関数型プログラミングの要素が強くなっていきますが、テーマは相変わらずFizzBuzzなので焦らずにまったりと生活を楽しんでください。
5日目 〜FizzBuzzでタプルに馴染む〜
4日目のプログラムでパターンガードで素直に剰余で分類できるようになりましたが、やはりパターンガードの記述は冗長に思えます。そこでタプルを用いてシンプルかつエレガントに書き換えて見ましょう。
1 | |
「タプル」は異なる型の値の集合であり、括弧()を用いて生成します。例えば(1, 2, 3)は(i32, i32, i32)型のタプルであり、(5, 3.1, "hoge")は(i32, f64, &str)型のタプルになります。f64は64ビット浮動小数点型で&strは「文字列スライス」と呼ばれています。ちなみに一日目に出てきたユニット()は実は要素を持たないタプルでした。要素が一つのタプルはあまり利用する場面がありませんが、作りたい場合は(1,)のように1つ目の要素のあとにカンマ,をつけます。こうすることで式をまとめるための丸カッコと区別することができます。
文字列スライスについて少し説明します。文字列スライスは文字列の一部を切り出したもので、固定長文字列を表す型を持ちます。具体的にはUTF8バイトシーケンスへの参照になっています。今まで何気なく使っていたprintln!("FizzBuzz")の"FizzBuzz"という表記は文字列リテラルと呼ばれ、型としては文字列スライスとして表されます[^6]。また、可変長文字列はヒープと呼ばれるメモリ空間に配置され、String型として区別されます[^7]。
Rustは性能に気を使う言語なので、静的領域に確保されたのか、スタックに確保されたのか、ヒープに確保されたのかを型を用いて表現します。一般的にRustのプログラムはオーバーヘッドが少ないスタック領域を優先的に使うようにして、必要なときにヒープが使えるようにデザインされています。
少し話が脱線しましたが話を上記のプログラムに戻すと、(x % 3, x % 5)は変数xの値をそれぞれ3と5で割った余りをタプルにしていて、型は(i32, i32)になります。パターンマッチのアームの中ではこのタプルのパターンに応じて分類を行っています。
(0, 0)というパターンは文字通り(0, 0)というタプル値と等しい場合にマッチングします。(0, _)というパターンはタプルの一つ目の要素が0で2つ目の要素は何でもマッチングします。_はワイルドカードパターンになっていて、このようにタプルのマッチングにも利用可能です。
パターンマッチはこのように内部構造を持ったデータ型に対して特に強力です。パターンマッチに関しては以前に記事を書いたので、さらに詳細について知りたい方は御覧ください。
[^6]: 文字列リテラルは正確には& 'static str型を持ちます。'staticはライフタイムと呼ばれており、プログラム初期化時に静的にアロケートされることを示しています。
[^7]: 可変長文字列から固定長の文字列を切り出して文字列スライスに変換することは可能です。
6日目 〜FizzBuzzでmatchが式であることを認識する〜
5日目のプログラムでタプルによるパターンマッチを身につけましたが、今度はprintln!マクロが冗長に思えてきました。どうにかしてprintln!を一箇所にまとめられないでしょうか? もちろん可能です。そのためにはmatchが式であることを理解する必要があります。
1 | |
matchが式であるとはつまり、評価した結果の値があるということです。そして変数は値に束縛できるので、その値をprintln!で表示することでprintln!を一箇所に集約することができます。しかし、以下のように単に変数sをmatchの評価値に束縛しようとするとコンパイルエラーになってしまいます。
1 | |
具体的なエラーは以下のようになっています。「incompatible types」とあるので型が合わずにエラーになっているようです。
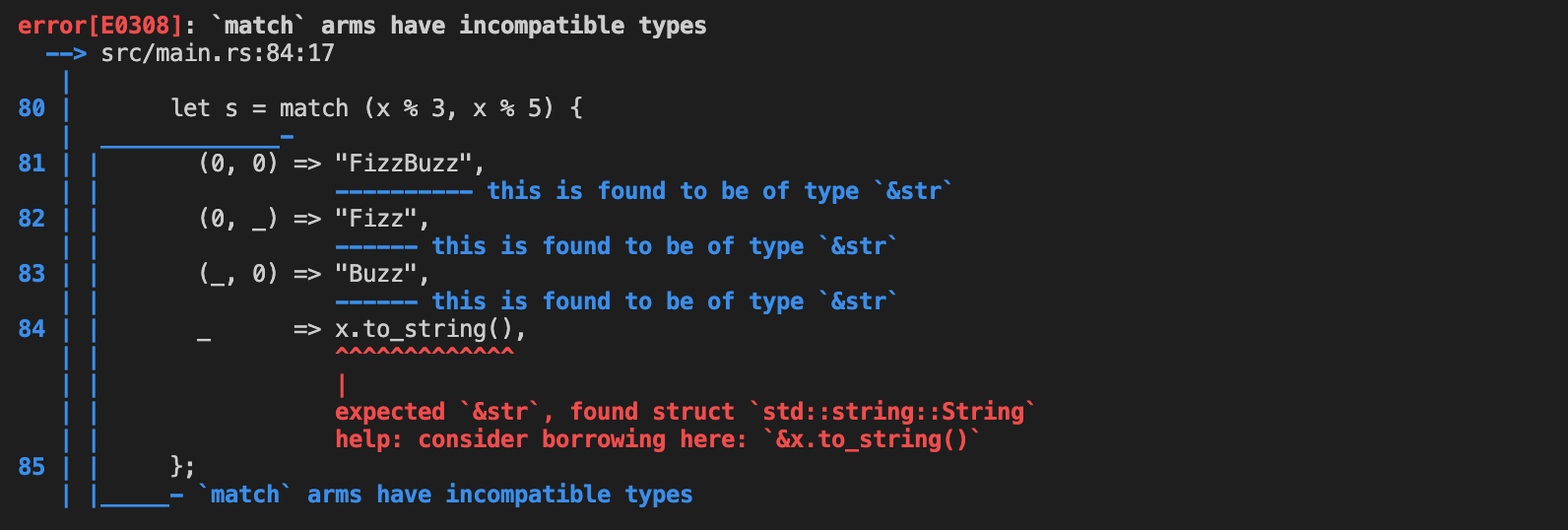
Rustは静的型付言語なので動的型付言語よりも型について強い一貫性が求められます。例えば今回のケースのようにmatchの中のアームの評価値は全て同じ型にする必要があります。そのことは理解していたつもりで最後のアームでx.to_string()として整数型を文字列型にしましたが、それでもエラーになってしまいました。
ここで5日目の出来事を思い出してください。そこでは文字列には固定長文字列の型(文字列スライスの型)である&strと可変長文字列の型であるStringがあることを述べました。つまり上記のエラーは文字列リテラルの型は&strであり、.to_string()で作成した文字列はString型なので、型が異なりエラーとなっている訳です。
ここではどちらかに型を寄せることでエラーを解決します。Rustで苦労するのはこの型合わせだと思いますが、エラーメッセージは比較的わかりやすいので一度理解してしまえば修正自体はそれほど難しくはありません。fizz_buzz6()では文字列リテラル(“FIzBuzz”等の文字列)を.to_string()でString型に変更することで対応しました。実は可変長文字列も&をつけて文字列スライスを切り出すことは可能ですが、それは7日目に説明します。
7日目 〜FizzBuzzで所有権と借用を意識する〜
6日目のプログラムでprintln!を一箇所にまとめることができたのですが、また新たに問題抱え込んでしまいました。これまで文字列リテラルとして静的に確保していた文字列を.to_string()で可変長文字列に変換しているので、毎回ヒープメモリへ文字列を確保することになってしまいました。100回くらいのループになら問題ないかもしれませんが、回数が多くなるほど性能に影響がでることは目に見えています。そこで今回はなるべく.to_string()を使わない方法を考えることにしました。
1 | |
上記の方法は、Rustの所有権と借用を正しく理解していないと思いつくことはできません。そして所有権と借用の概念はRustの際立った特徴になっているので、快適なRustライフを送るためにもこれらを理解できるようになりましょう。所有権の規則は以下のとおりです。
- Rustの各値は、所有者と呼ばれる変数と対応している。
- いかなる時も所有者は一つである。
- 所有者がスコープから外れたら、値は破棄される。
以下で具体的に確認してみます。まずは「常に所有権はひとつ」というルールを守るためのムーブセマンティクスについて説明します。
1 | |
「ムーブセマンティクス」とは簡単にいえば所有権の移動という意味であり、上記の例ではs2へs1を代入することにより所有権が移動しています。エラーメッセージは以下のようになりどこで所有権が移動し、どこで利用しようとしてエラーになったのかひと目で分かるようになっています。

次に代入以外でムーブセマンティクスが有効になる例を紹介します。それは関数の引数と戻り値になります。
1 | |
上記ではまず作成された文字列の所有者はs1になり、test_print()が呼び出され、文字列の所有者はs1からtest_print内のmsgになります。次にmsgはfn test_printの戻り値としてそのまま返却されます。このとき所有権も移動して、呼び出し元のs2が新たな所有者になります。つまり所有者はs1 -> msg -> s2と移動しており、単一所有者の原則が守られていることが分かると思います。
ちなみにRustの関数は最後に評価された式もしくは文の評価値が戻り値になる仕様です。文の評価値は常にユニット()になります。そしてセミコロン;は式を強制的に文(正確には式文)に変えるようになっています。そのため、例えば上記のtest_print関数の最後の行をmsg;としてセミコロンをつけてしまうと、式が式文に変換されてしまい、ユニット()が戻り値となりますが、そうすると関数宣言でStringが戻り値になっていることと矛盾するのでコンパイルエラーになります。
このように所有権を明確にすることでリソースの多重解放によるエラーをコンパイル時に検出することができるようになります。また、リソースの利用に関するある種の競合をコンパイル時に検出してエラーにすることができます。この所有者は一つという性質は例えばC++のunique_ptrでも実現できますが、unique_ptrの利用がオプションなので、変数に対する不正なアクセスを防ぎ切ることはできません。その点Rustは言語レベルで所有権の規則を徹底しているので、不正な変数へのアクセスをコンパイル時に確実に防いでくれます。
ただ毎回、所有権を移動させてしまうと不便なケースもあります。例えば上記の例で言えばs1の値をtest_print関数で利用したあとにs1と同じスコープで再利用したい場合には、必ずtest_print関数の戻り値として所有権を移動させて、元に戻す動作にする必要があります。こういうケースではRustの「参照」の機能を利用すると便利です。参照はアンパサンド&を変数名につけることで作成できます。
1 | |
参照は型名でも区別され、String型の参照は&String型になります。この参照を利用して、所有権を移動させずに定期間だけ値をレンタルすることを借用と呼びます。借用には以下のルールがあります。
- 参照は値よりも長く生存してはならない
- 参照が有効なスコープはライフタイムと呼ばれる
- 値が共有されている間は値の変更を許さない
上記のルールを守ることによりデータの競合を防ぎつつ、安全な共有を実現できます。次に、スコープと値の破棄について説明します。
1 | |
コメントのとおり、変数sのスコープは変数が宣言されてから中括弧の終わり}までなので、「コンパイルエラー」とコメントされた行ではsは破棄されておりアクセスできません。この「所有者がスコープから外れたら、値は破棄される」という性質は他の一部の言語でも見ることができます。この機能はよく「ローンパターン」と呼ばれており、C++のRAII、Javaのtry-with-resources、C#のusing、ScalaのUsing、Goのdefer等がそれにあたります。
ようやく、ここまでの説明でfizz_buzz7()を説明する下地が整いました。まずfizz_buzz7を一部切り出して変更した以下の例はコンパイルエラーになりますが、エラーの理由を考えてみてください。
1 | |
「型があっていないから」、と答えた方は残念ながら不正解です。&x.to_string()においてx.to_string()はString型であり、アンパサンド&をつけて参照をとると&String型になります。そして”FizzBuzz”のような文字列リテラルは&str型になるので確かに型はあっていません。しかし、それはRustの「型強制」という仕組みで&String型は&str型に変換されてしまうので型の問題はなくなるのです。
型の問題ではないとすると何が問題かというと「ライフタイム」の問題となります。つまりx.to_string()でString型の値が作成されますが、その値が有効なスコープはmatchのアームの中だけなので値はそこで破棄されます。しかし、&x.to_string()でその破棄されたはずの値の参照を返そうとしているので「参照は値よりも長く生存してはならない」というルールに反してエラーになるのです。単純に.to_string()した値を返すだけならムーブセマンティクスが働いてそのまま値がムーブされますが参照は所有権を移動しないのでこのような挙動になります。
この問題は以下のようにより広いスコープを持つ変数に束縛させてから参照をとることで解決できます。
1 | |
このようにすることで、参照&tmpのライフタイムは変数sと同じであり、それは変数tmpの有効スコープ内であるので、借用ルールの制約をみたすことができます。
思ったより長かったですがこれでfizz_buzz7を理解することできるようになったと思います。恐らくこの所有権と借用がRust中級者の一番のハードルだと思われるのでしっかりと理解を深めるようにしてください。
8日目 〜FizzBuzzで高階関数とクロージャに目覚める〜
7日目のプログラムで性能を犠牲にしないFizzBuzzになりましたが、直感的には分かりづらくなりました。それは元のFizzBuzzを表示するというロジックとは関係ない性能の都合上のtmp変数を導入したことに原因があります。この辺はトレードオフの問題ですが、やはりメンテナンス性を重視した設計がしたくなりました。そこで唐突に天から啓示を受けました。高階関数とクロージャに目覚めよと。
1 | |
まずは関数とクロージャの違いについて説明します。クロージャ以下のとおり関数と見た目と機能はよく似ていますが違いがいくつかあります。
1 | |
1つ目の違いは、関数は引数の型や戻り値の型を省略できませんが、クロージャは大抵は省略できることです。「大抵」と書いたのは型推論に失敗してコンパイラに型を書けと怒られる場合もあるからです。
2つ目はクロージャは外部の変数を利用できることです。上記の例ではdouble_closureではクロージャ本体の外側の変数twoを利用しています。このときクロージャは変数を環境としてキャプチャしているので、クロージャの中で利用可能になっています。関数は環境をキャプチャできないので外部の変数は利用できません^8。
3つ目は関数には「名前」があり、クロージャには「名前がない」ということです。クロージャには名前がないので変数に束縛して利用するか、そもそも名前が必要がない箇所で用いられます。名前が必要ない箇所とは定義して即時実行する場合や「高階関数」の引数や戻り値として利用する場合です。
最後の違いはクロージャの波括弧}後にはセミコロン;が必要なことです。これはクロージャというよりもlet宣言と関数の違いになります。
Rustのクロージャは他の言語では「無名関数」、「匿名関数」、「ラムダ」と呼ばれる場合がありますが、基本的には同じ役割を果たしていると考えて差し支えありません。ただし一般的な「クロージャ」という用語は「環境をキャプチャする」という側面を強調していることは頭の片隅に留めておくべきかもしれません^9。
次に、高階関数について説明します。高階関数は関数を引数にとるか、関数を戻り値として返す関数です。つまり「関数」を「値」としてやりとりする関数です。ここでいう「値としての関数」にはクロージャも含みます。以下は高階関数のmapとfor_eachの使用例です。
1 | |
上記の例ではレンジ(1 ..= 5)に対してmapを呼び出しており、レンジの各要素にdoubleを適用しています。doubleは引数を2倍にするので各要素は[2,4,6,8,10]になりmapはそれをイテレータとして返します。そしてイテレータに対してfor_eachを呼び出すとイテレータが返す各要素に対して受け取った関数を適用します。上記の例ではクロージャを適用しています。クロージャの中身はprintln!の適用なので、結果的に出力は以下のようになります。
1 | |
mapもfor_eachも動作はよく似ていますが、違う点は戻り値としてイテレータを返すかどうかです。mapはイテレータを返すので何回もmapを続けることができますが、for_eachはユニット()を返すのでその後にmapやfor_eachを続けることはできません。つまりmapは中間で使われることを意図しており、for_eachは終端で使われることを意図してます。Rustではこの使い分けを明確にしており、mapはイテレータアダプタと呼ばれており、for_eachはコンシューマと呼ばれています。イテレータおよびイテレータアダプタの作用は基本的に怠惰(lazy)であり^10、コンシューマが消費するまで作用しません。このことは以下を実行してみるとよく分かると思います。
1 | |
上記の実行結果は以下のようになります。構文上はmapがfor_eachよりも先なのでmapが先に呼ばれそうですが、mapは怠惰なのでfor_eachで必要になったときに処理を実行するようになっているので、結果的にin mapとin for_eachが交互に出力されるようになります。
1 | |
ここまでの説明でfizz_buzz8はほぼ理解できるようになるのですが、最後に一点だけformat!マクロについて補足します。このマクロはprintln!マクロと似ていますが結果を画面に出力するのではなくString型の文字列で返します。単純な文字列なら.to_string()でも良いですが2つ以上の変数から文字列を作成したい場合に重宝します。
9日目 〜FizzBuzzで畳み込みを実践する〜
8日目のプログラムでクロージャと高階関数に目覚めてしまった訳ですが、他にもFizzBuzzで利用できそうな高階関数がないかと探してみると面白そうなものが見つかりました。それがfoldであり畳み込みと呼ばれる処理を実現します。
1 | |
まずは簡単な例でfoldを確認してみたいと思います。以下の例はfoldを用いて1から5の和を求めるコードです。
1 | |
foldの挙動はイテレータから順番に値を取り出して、前回の計算結果と取り出した結果を元に出した計算結果を次回に繰り越すことを繰り返し、一番最後の計算結果がfoldの値になります。一番最初の計算には「前回の計算結果」がないので初期値を与えます。上記のプログラムでは具体的には(((((O + 1) + 2) + 3) + 4) + 5)のような数式で計算していることになります。
foldで行われるような処理は一般的は畳み込みと呼ばれますが、Rustのfoldは左畳み込みとなっており、先頭から順に要素を取り出して計算を行います。これとは別に右畳み込みというものもあり、要素を逆順で取り出して処理します。
以上によりfizz_buzz9ではfold内では簡易な式で表現すると以下のような順序で文字列が結合されて、最終的にはprintln!表示されます。
1 | |
第三章 Truth of Rust
ここからはRustの上級者向けの章になります。これまでは詳細な説明を加えていましたが、ここからはヒントと簡単な説明のみになります。上級者になるには調べる力も必須になってくるのでぜひチャレンジして理解できるようになりましょう。以下は参考になるリンクです。
- The Rust Programming Language
- Rustの日本語ドキュメント
- Rust Language Cheat Sheet
- Comprehensive guide to the Rust standard library APIs
10日目 〜FizzBuzzでコレクションとジェネリクスに気付く〜
9日目のプログラムでfoldの魅力に気づきましたが、文字列を+演算子で結合していくやり方は自由度が高すぎてFizzBuzzではやりすぎなのではと思うようになりました。そこでfoldで行っていた文字列結合をもっとシンプルに行う処理そ探していたらjoinを見つけました。
1 | |
上記のプログラムの理解のポイント以下になります。
- コンシューマである
collect - 配列型のコレクションである
Vec Vecとセットでついてくるジェネリクスの理解joinによる結合処理
11日目 〜FizzBuzzでレムとの邂逅〜
10日目のプログラムでなんとなくfz関数を眺めていると引数の型がi32型に固定されていることに気づきました。せっかくジェネリクスを覚えたのでfzをジェネリックにしてu32型やi64型にも対応できるようにしたくなりました。
1 | |
上記のでRunがRamになっているのは仕様です。どうしてもRemと一緒に登場させたかったのです。優しくスルーして頂けると幸いです。
上記のプログラムのポイントは以下です。難易度が跳ね上がりましたが、どうか挫けずに次の日の朝を迎えられるよう頑張ってください。
- ジェネリック関数の実装
- トレイト境界
- FizzBuzzで必要な演算(剰余(
Rem)、0との比較(Eq)) CopyトレイトとToStringトレイトの役割
12日目 〜FizzBuzzでトレイトと戯れる〜
11日目のプログラムでトレイトの存在に気づき、トレイトを生かしてFizzBuzzを実装してみたくなりました。
1 | |
上記のプログラムのポイントは以下です。RustのトレイトはHaskellの型クラスに相当するものです。Javaのような継承ベースのオブジェクト指向言語から来た方には理解が難しいかもしれませんが、一度慣れると多くのメリットに気づけると思います。
- 構造体の定義と実装
- メソッド定義と関連関数
- トレイトの定義と構造体への実装
13日目 〜FizzBuzzをアドホックに改造する〜
12日目のプログラムではToFzStrはi32型にしか実装していませんでしたが、他の型にも実装したくなりました。
1 | |
上記のプログラムは12日目と被る定義は省略しています。プログラムの全体は「Run」のリンク先を見てください。
ポイントは以下になります。
- トレイトを複数の型への実装してアドホック多相性を確認する
14日目 〜FizzBuzzで無限列に畏怖する〜
13日目のプログラムまでは1から100までのFizzBuzzに対応してきましたが、もっと大きなFizzBuzzも試してみたくなりました。
1 | |
上記のプログラムは以前と被る定義は省略しています。プログラムの全体は「Run」のリンク先を見てください。
ポイントは以下になります。
- 無限の数値列の生成
(1..) takeによる切り出し
15日目 〜FizzBuzzで再帰的に死に戻る〜
14日目のプログラムで無限の奥深さに惹かれました。そしてとうとう無限を表現する禁忌の手段、再帰の沼にハマってしまったのです。こうなるともう元の生活に戻るのは困難でしょう。終わりの始まりです。
1 | |
ポイントは以下になります。
- 再帰を理解する
- 末尾再帰最適化について調べ始める・・・^11
- 素直にイテレータを使ったほうが幸せだと気付く
まとめ
Rustは学習曲線が急峻だと言われています。学ぶべきコンポーネントが多く個々が密接に関連していて、ラスボス感漂う借用チェッカーまでいるからです。そのため約束した朝は遠く、絶望という病に侵されるかもしれません。脳が震えるかもしれません。でもFizzBuzzがいます。どんなに辛く苦しいことがあって負けそうになってしまっても、世界中の誰も信じてくれなくて、自分自身を信じられなくなってしまっても、FizzBuzzが側にいます。ここから始めましょう。イチから、いいえ、FizzBuzzから。
while,ifforとレンジ- パターンマッチ
- タプル
- 所有権と借用
- 高階関数とクロージャ
- 畳み込み
- コレクションとジェネリクス
- トレイトとトレイト境界
- アドホック多相性
- 無限列
- 再帰
Rust生活をFizzBuzzから始めることで上記の学びが少しずつ得られると信じています。そして絶望に抗う賭けに勝ち、鬼がかった未来を手に入れましょう。
君を見てる。
君が見てる。
だから俯かない。
ここから、FizzBuzzからはじめよう。
プログラマの物語を。
– FizzBuzzから始める、Rust生活を。
(本記事は、某ラノベ[^12]のパロディとして書かれており、設定およびセリフの一部を改変して借用しています。ちなみに本記事の初出は4/1であり、お察し頂ければと思います。)