Contextual Abstractionsで様々なコンテキストをうまく抽象化する

プログラミングでは様々な「コンテキスト」を扱う必要が出てきます。コンテキストをうまく扱えないと冗長な記述が必要になったり、コンテキストが複雑になりすぎて混乱を招いたりします。特にコンテキストの引き回しは様々なプログラミング言語やフレームワークで出てくるパターンですが、安易に使うと複雑性、冗長性の増大や密結合等さまざまな問題を引き起こすことが知られています。しかしScala 3の目玉機能であるContextual Abstractions(コンテキスト抽象化) を使えばこの問題を鮮やかに解決できます。
本記事ではContextual Abstractionsがなぜコンテキストをうまく扱うことができるのかを説明したいと思います。
はじめに
Scala 3で新しく 「コンテキスト抽象化」 という機能が入ります。この機能は従来の「Implicits」と呼ばれる機能を再設計し、さらに大幅に強化したものになっています。「コンテキスト抽象化」はScala 3を特徴付ける非常に魅力的な考え方なので、従来のScalaやImplicitsを知らない人でもなるべく分かるように説明したいと思います。
コンテキスト抽象化の基本
コンテキスト抽象化の本質は 「コンテキストの引き回し」に対するエレガントな回答 であり、Scala 3のusing句とgivenインスタンスの仕組みが大きな役割を果たしています。このことを次の節から順に説明していきます。
コンテキスト
コンテキストは日本語で書くと「文脈」になり、前後の繋がりや背景を意味します。プログラミングでは 特定の範囲で有効な複数の処理で共通する情報 をコンテキストとしてよく扱います。
変数名としてはよくcontextの省略形であるctxが用いられる場合が多いですが、その他にもinfoとかconfig等のもう少し用途を限定した名前が割り当てられる場合があります。
例えば以下の例ではコンテキストとしてctxという変数を用意し、コンテキストの情報として"sunny"を代入して複数回利用しています。
1 | |
上記の例ではコンテキストをローカルの変数として用意していますが、「コンテキスト」自体は情報の有効範囲や使われ方に対する性質を意味しているので、実際のコンテキストには様々なものが考えられます。
コンテキストの引き回し
シンプルなコンテキストは単一の関数のスコープ内で利用もできますが、一般的にはコンテキストを関数の間で受け渡して 複数の関数でコンテキストを共有する用途 でよく利用されます。これをコンテキストの引き回し といいます。
以下の例ではコンテキストctxを親関数から孫関数まで引き回しています。
1 | |
コンテキストに複数の情報を持たせたい場合は専用の 「型」 を用意します。
以下は専用のContextAという型を用意してコンテキストの情報を詰め込んでいます。
1 | |
図にすると以下のようになります。
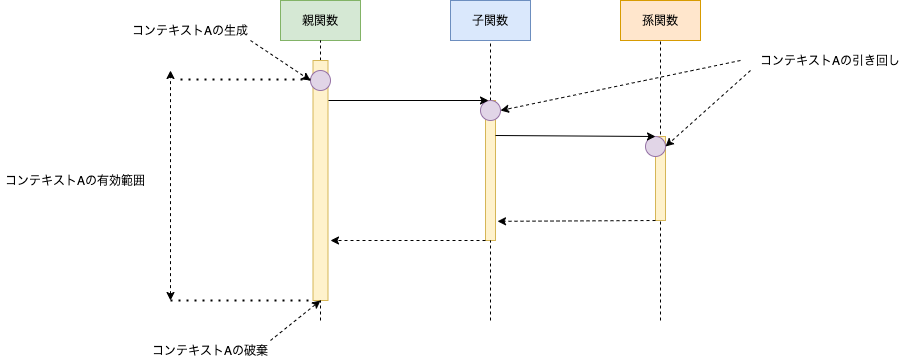
コンテキストの型は非常に便利ですが、コンテキストに詰め込みたい情報が増えてくるとコンテキストに依存する関数の間に複雑な依存関係を生み出し、密結合となってしまいます。密結合の関数は単体テストやメンテナンスがしづらく非常に厄介です。
コンテキストを型で分割する
前述のとおり一つのコンテキストに情報を詰め込みすぎると単体テストやメンテナンスが面倒になるので都合のいい単位で分割することにします。
以下の例では元々のコンテキストをContextAとContextBの2つに分割しています。そしてctxBは子関数と孫関数でしか使われないので、子関数で定義することにします。
1 | |
図にすると以下のようになります。
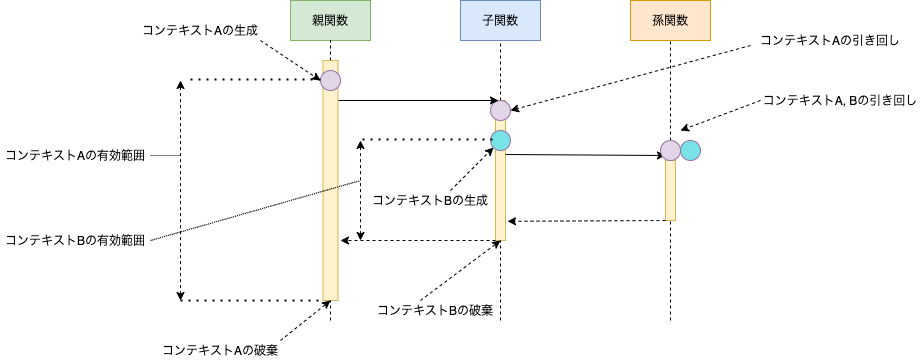
型によるコンテキストの特定(usingとgiven)
ここからがScala 3に特化した内容になりますが、using句を使うとコンテキストパラメータと呼ばれる特殊なパラメータを関数が受け取ることができるようになります。そしてコンテキストパラメータでは 「型」 を基準にgiven インスタンスをスコープ内で探して自動的に補完します。
以下の関数定義でusingが使われている箇所がコンテキストパラメータになります。コンテキストパラメータはもし、スコープ内に同じ型のgivenインスタンスがあった場合に呼び出し時に省略可能です。
1 | |
さて、ここまでの説明をもとにこれまでの親関数、子関数、孫関数を書き直すと以下のようになります。
1 | |
図にすると以下のようになります。givenとusingの対応に注目してください。
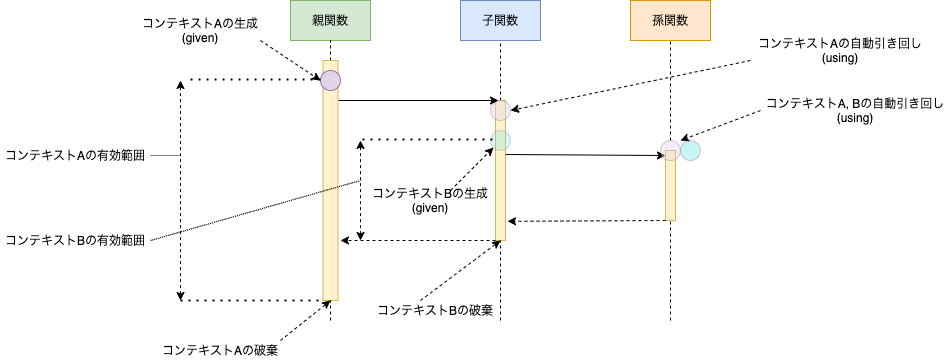
usingとgivenにおける変数名の省略とsummonメソッド
usingとgivenでは変数名を省略して型名のみ記述することができます。この場合summonメソッドと型名を用いてインスタンスにアクセス可能です。summonは「召喚する」という意味で、省略された変数に格納されるはずだったインスタンスを強制的に「召喚」します。
1 | |
一般的にはsummonメソッドを使うと記述が長くなるので、summonメソッドを使わなくて済む場合にだけusingやgivenの変数名を省略します。
例えば上記の子関数の場合、元々の関数宣言はdef childFunction()(using ctxA: ContextA)でした。しかしctxAは子関数では利用されず、そのままgrandchildFunctionに引き回されて省略されたコンテキストパラメータに補給されるだけなので、省略が正解です。
しかし子関数のContextBに関してはその後すぐにsummon[ContextB].yearで利用しており元のctxB.yearの方が短く簡潔になるので、省略しないほうが良かったと考えられます。
コンテキスト抽象化
コンテキスト抽象化の基本的なアイデアは前節で説明したgivenとusingに集約されています。具体的には以下の4つからなります。
- コンテキストを「型」として定義
- コンテキストを受け取る関数を定義(
using句) - コンテキストの生成(
givenインスタンス) - コンテキストを受け取る関数の呼び出し(コンテキストの自動引き回し)
コンテキスト抽象化の本質はこの4つのステップが分離されていて、コンテキストの有効範囲がコントロールされているということです。分離されているということは別々のファイルで定義されてもいいということであり、有効範囲がコントロールされているというのは、直接定義されたスコープかインポートしたスコープの範囲でしかコンテキストが有効にならないこと意味しています。
それでは具体的にファイルを分割して、コンテキストがうまく抽象化されてきちんと制御されていることを確認します。
1 | |
1 | |
1 | |
1 | |
1 | |
importベースの各ファイルの依存関係を図にすると以下のようになります。
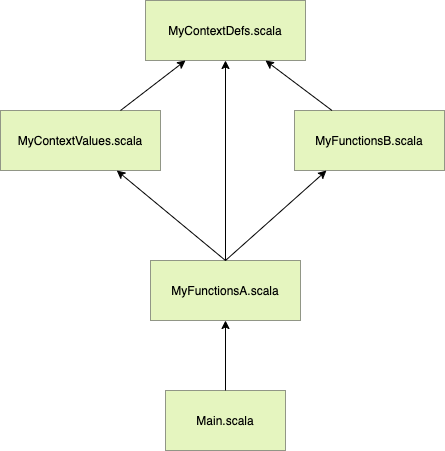
コンテキスト抽象化を行うと上記のように、各ファイルが疎結合になり修正による影響範囲を抑えることができます。またどのgivenインスタンスをインポートするかを選択可能になるのでカスタマイズの柔軟性が飛躍的に向上します。これはライブラリの作成者とライブラリの利用者の両者に福音だと思います。また当然ですがコンテキストパラメータの省略により冗長な記述が避けられるのも大きなメリットです。
コンテキスト抽象化の高度な機能
次の節からはコンテキスト抽象化の高度な機能として拡張メソッドと型クラスの2つの機能を紹介します。
特定の型にコンテキストを追加する(拡張メソッド)
コンテキスト抽象化の高度な機能として拡張メソッドがあります。拡張メソッドを使えば既存の型に修正を加えることなくメソッドを追加できます。
もちろん無制限に追加できるわけではなくて型の制約と有効範囲が存在するので、考え方はコンテキスト抽象化の発展的なものと捉えることが可能です。
具体的にはextensionキーワードを用いて型を拡張します。例えば以下の例ではPersonという型にextensionキーワードでprofileというメソッドを拡張しています。
1 | |
上記のようにprofileメソッドを定義するのに直接Personクラスを修正する必要はありません。このおかげでPersonを利用している他の箇所には影響はありません。影響があるのはextensionで定義した拡張メソッドのスコープ内のみになります。
オブジェクト指向における継承とも異なる事に注意する必要があります。拡張メソッドと継承のどちらも既存の型にメソッドを追加することができますが、継承は以下のように新たな型(サブクラス)を定義するため追加したメソッドを呼ぶためにはサブクラスのインスタンスを生成してメソッドを呼び出す必要があります。
1 | |
オブジェクト指向の継承と拡張メソッドの違いを図にすると以下のようになります。
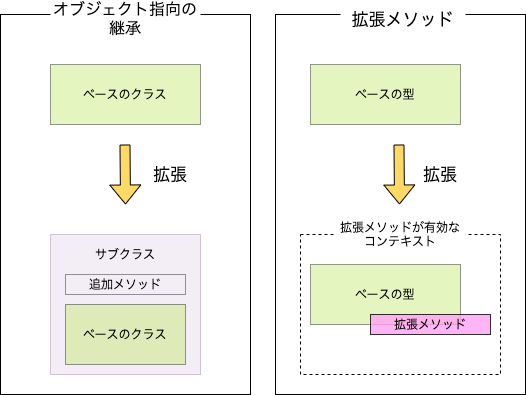
上記のように拡張メソッドは既存の型を継承して新しい型を作成するわけではないので、is-a関係なども気にする必要はなくなります。
特定のコンテキストを持つ「型」を定義する(型クラス)
拡張メソッドでは特定の型を拡張できましたが、時には複数の型に共通するメソッドのシグネチャを定義してそのメソッドの実装は型ごとに行いたい場合があります。このような機能は「型クラス」^1と呼ばれています。
以下の例ではPersonとJapaneseというふたつの型に対して、CanGreetという型クラスを実装しています。この例でも前述の拡張メソッドと同じくPerson/JapaneseとCanGreetの間に継承関係は存在しません。
1 | |
型クラスの考え方を図にすると以下のようになります。
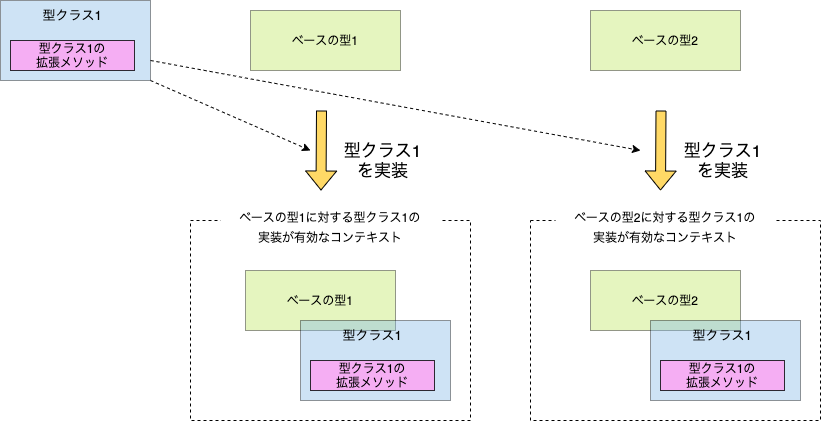
重要なのは型クラスの実装はベースの型に対して固有になるということです。このためベースの型を後付で柔軟に拡張することができます。このような性質は アドホック多相性 とも呼ばれており、HaskellやRustやSwift等でも利用できる汎用的な概念です。
前述の拡張メソッドと型クラスの大きな違いは 拡張メソッドは単一の型を拡張することができますが、型クラスは複数の型を拡張できる という点です。 もちろん拡張メソッドも頑張れば個々の型を同じように拡張できますが拡張メソッドが同じインターフェースをもつことをコンパイラが保証できないので、その点が型クラスが必要な理由となります。つまり 「型クラス」は「型」に対するインターフェースの役割を果たしている ということができます。
型クラスを受け取る関数
関数を定義する場合、usingを利用したコンテキストパラメータを以前に紹介しましたが、コンテキストパラメータでは型クラスも受け取ることができます。
以下のコードは型クラス「CanGreet」をコンテキストパラメータとして受け取るgreeting関数を定義しています。
1 | |
greeting関数は以下のような糖衣構文で記述することもできます。この記法は 「コンテキスト境界」 と呼ばれおり、型パラメータTが型クラスとしての制約CanGreetを満たすという関係がより分かり易く記述できます^2。
1 | |
コンテキスト抽象化について、さらに知りたい方へ
コンテキスト抽象化ではさらに以下のような高度な機能もあります。
- 型クラスの導出(Type Class Derivation)
- 多元的等価性(Multiversal Equality)
- コンテキスト関数(Context Functions)
- 暗黙の変換(Implicit Conversions)
上記をもっと詳しく知りたい方は以下もご参照ください。
まとめ
Contextual Abstractions(コンテキスト抽象化)について説明しました。コンテキスト抽象化の本質は 「コンテキストの引き回し」に対するエレガントな回答 であり、プログラムの疎結合化、柔軟性の向上、シンプル化 に貢献します。さらに発展として 「型のコンテキスト」を抽象化した「拡張メソッド」や「型クラス」にまで応用が広がっている強力な概念 であり、プログラミングにおける有用な武器であることに疑う余地はありません。
「コンテキスト抽象化」という用語は恐らくScala 3で初めて出てきたものですが、内部の細かい機能は以前からあるImplicits等の機能の再設計となっています。さすがに再設計だけあって恐らく Scala 3以外でここまでコンテキスト抽象化について考えられているプログラミング言語はほとんどないものと思われます。
ただし再設計といっても非常に多くの部分が見直されたり整理されたので 従来の知識を前提とせず理解できるように 「コンテキスト」という概念から始めてイチから説明を積み上げています。本記事で用いたソースコードは以下のリポジトリの「examples」に登録してあるので興味がある方はご参照ください。

Scala 3は2021/2/17に3.0.0-RC1(リリース候補)が登場し、今年の前半から中盤にかけて正式リリースされる予定とアナウンスされています[^3]。コンテキスト抽象化以外にもScala 3では新機能が目白押しなので、リリースに向けて少しずつ機能をキャッチアップしていければと思っています。
本記事が、コンテキスト抽象化やScala 3に興味がある方の一助になれば幸いです。
[^3]: Scala 3 - Crossing the finish line | The Scala Programming Language
参考文献
- New in Scala 3
- Scala 3の新機能をさっとおさらいしたい人向けです。
- Scala 3 Book
- 無料で読めるScala 3本です。現時点でScala 3に対して最も読みやすい資料だと思います。
- Scala 3 リファレンス
- Scala 3を全体を通して知りたい方は目を通してください。
- Scala3に入るかもしれないContextual Abstractionsを味見してみた(更新・追記あり) - Qiita
- 過去にContextual Abstractionsを試したときの記事です。中身は最新の3.0.0-RC1にアップデートしてあります。
- Scala 3、Pythonのようにインデントベースの構文で書けるようになるってよ! - Qiita
- 過去に書いたScala 3のインデントベースの構文の記事です。以前のScala 2をご存じの方でインデントベースの構文に違和感を覚えた人向けです。