LinuxでGPU環境を構築して暫く経ちました。今回いろいろ古くなった環境を再構築する機会があったので、Linuxにおける機械学習の環境構築とCIFAR-10でディープラーニングに至る道程について簡単に記録に残しておくことにしました。
対象読者 本記事は、LinuxでGPUを用いた機械学習の環境を構築してみたい方を対象にしています。また、MLOpsに興味があり、機械学習基盤の構築に興味がある方にもおすすめします。本記事では実際に機械学習の環境を構築してディープラーニングで画像分類をおこなうところまでの手順を説明します。その際以下の知識があったほうがより深く理解が出来ますが、本記事を読むのに必須ではありません。
Kubernetes
JupyterLab
TensorFlow
Keras
CNN(Convolutional Neural Network)
マシンの準備 まずは機械学習用のマシンを調達します。マシンはLinuxが動作してNVIDIAのグラフィックボードを認識できれば問題ないです。グラフィックボードはなるべく新しいものの方が計算速度が速いのでいいと思います^1 。
OSのインストール Ubuntu 18.04を利用します。以下からダウンロードしてインストールします。
NVIDIAドライバのインストール 「ソフトウェアとアップデート」を起動して「追加のドライバー」タブから「プロプライエタリ、検証済み」のドライバを選択して「変更の適用」をします。適用後に再起動してください。
nvidia-smiコマンドが利用できて以下のような感じになればOKです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ nvidia-smi
以下の手順どおりに実行します。
以下はコマンドの抜粋です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ sudo apt-get remove docker docker-engine docker.io containerd runc"deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"
インストール後は「docker version」のコマンドで確認します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ sudo docker version
以下に従って行います。
1 2 3 4 5 $ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
デフォルトのコンテナランタイムを変更するため/etc/docker/daemon.jsonに以下を記載します。
1 2 3 4 5 6 7 8 9 { "default-runtime" : "nvidia" , "runtimes" : { "nvidia" : { "path" : "/usr/bin/nvidia-container-runtime" , "runtimeArgs" : [ ] } } }
dockerを再起動します。
1 $ sudo systemctl restart docker
以下のコマンドでdockerからGPUが見えているか確認します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ docker run nvidia/cuda:10.0-base nvidia-smi
kubectlのインストール 以下の手順でインストールします。
1 2 3 4 $ curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectlchmod +x ./kubectlmv ./kubectl /usr/local/bin/kubectl
Minikubeのインストール 以下に従って行います。
1 2 $ curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && chmod +x minikubecp minikube /usr/local/bin && rm minikube
以下のコマンドでMinikubeを実行します。--vm-driver noneがポイントでこれをつけるとホスト上のDockerでKubernetesが実行されます。
1 sudo -E minikube start --vm-driver none
Dockerイメージの作成 まずは機械学習用のDockerfileを作成します。Dockerfileは以下のとおりです。
Dockerfile 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 FROM nvidia/cuda:10.0 -cudnn7-develWORKDIR / ENV PYENV_ROOT /.pyenvENV PATH $PYENV_ROOT/shims:$PYENV_ROOT/bin:$PATHRUN apt-get update && apt-get install -y \ curl \ git \ unzip \ imagemagick \ bzip2 \ graphviz \ vim \ tree \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* RUN git clone git://github.com/yyuu/pyenv.git .pyenv RUN pyenv install anaconda3-2019.10 RUN pyenv global anaconda3-2019.10 RUN pyenv rehash RUN pip install tensorflow-gpu==2.0.0 gym RUN conda install -c conda-forge jupyterlab RUN conda install -c anaconda pandas-datareader RUN conda install -c anaconda py-xgboost RUN conda install -c anaconda graphviz RUN conda install -c anaconda h5py RUN conda install -c conda-forge tqdm RUN mkdir /jupyter WORKDIR /jupyter ENV HOME /jupyterENV LD_LIBRARY_PATH $LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64ENV SHELL /bin/bash EXPOSE 8888 ENTRYPOINT ["jupyter" , "lab" , "--ip=0.0.0.0" , "--no-browser" , "--allow-root" , "--NotebookApp.token=''" ]
ポイントは以下のとおりです。
ベースイメージとしてnvidia/cuda:10.0-cudnn7-develを指定
TensorFlow 2.0が動作可能なCUDAとcuDNNを指定
pyenvでAnaconda をインストール
Anacondaでデータサイエンスに必要なパッケージの全部入りをざっくり入れる
minicondaで細かく指定して入れる方法もある
condaでJupyterLabをインストールpipでtensorflow-gpu(2.0.0)をインストール
まだAnacondaに最新パッケージがなかったのでpipでインストール
LD_LIBRARY_PATHにCUPTIのライブラリのパスを指定
TensorFlowで利用されるのでパスを通しておく
ENTRYPOINTでJupyterLabが起動するように指定する
次に以下のコマンドでイメージのビルドを行います。
1 docker build -t ml/all:v0.1 .
以下のコマンドでイメージが作成できているかどうか確認します。
1 2 3 $ docker image ls ml/all
デプロイメントの作成 以下のようなyamlファイルを作成し、上記で作成したイメージをMinikubeにデプロイします。
ml-deploy.yaml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 apiVersion: apps/v1 kind: Deployment metadata: name: ml-deployment labels: app: ml-deploy spec: replicas: 1 selector: matchLabels: app: ml-deploy template: metadata: annotations: kubernetes.io/change-cause: "modified at 2019-10-20 05:50:40 +0900" labels: app: ml-deploy spec: containers: - name: ml-deploy image: ml/all:v1.0 ports: - containerPort: 8888 volumeMounts: - name: notebook mountPath: /jupyter imagePullPolicy: IfNotPresent volumes: - name: notebook hostPath: path: /home/jupyter/ml-all type: Directory
以下のコマンドでデプロイメントの作成を行います。
1 kubectl apply -f ml-deploy.yml
以下のコマンドでデプロイメントが作成されていることを確認します。
1 2 3 $ kubectl get deployments
サービスの作成 以下のようなyamlファイルを作成し、上記で作成したイメージをデプロイメントをサービスとして公開します。
ml-svc.yaml 1 2 3 4 5 6 7 8 9 10 11 12 13 kind: Service apiVersion: v1 metadata: name: ml-svc spec: selector: app: ml-deploy ports: - protocol: TCP port: 8888 targetPort: 8888 nodePort: 30001 type: NodePort
以下のコマンドでサービスの作成を行います。
1 $ kubectl apply -f ml-svc.yml
以下のコマンドでサービスが作成されていることを確認します。
1 2 3 4 $ kubectl get services
サービスの作成はkubectlのexposeコマンドを用いても行うことができます。
JupyterLabでノートブックを作成 ブラウザで以下のアドレスにアクセスします。
1 http://(minikubeが起動しているマシンのIPアドレス):30001/
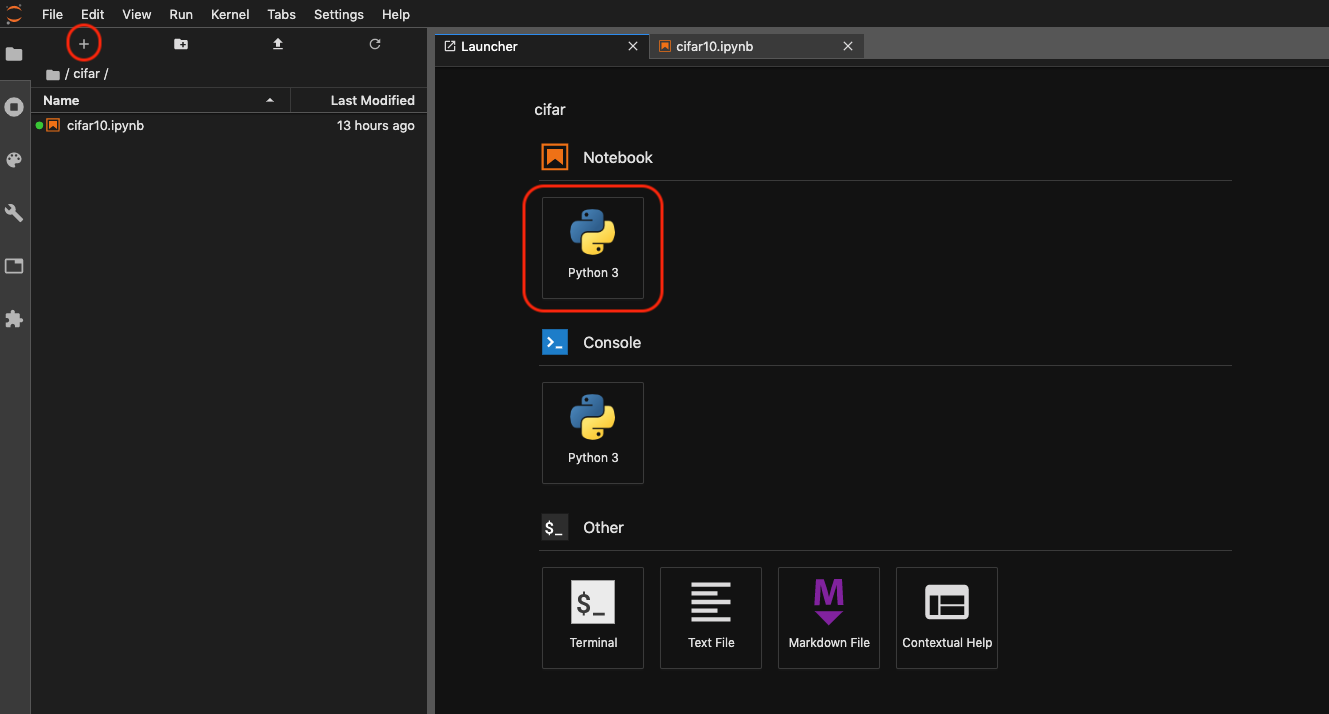
+ボタンを押して、Lancherを起動し、Python3のノートブックを作成します。
TensorFlow 2.0 with Kerasで画像分類(CIFAR-10) ようやくお待ちかねのディープラーニングのターンです。今回はようやく最近正式リリースされたTensorFlow 2.0に密に統合されたKerasのAPIを利用してCIFAR-10の画像セットを用いて画像分類を行います。
ソースコードはkeras/cifar10_cnn.py をベースにtensorflow対応や可視化表示のコードを加えたものになります。先程作成したノートブックに貼り付けて実行してください。適当にセルに分割して実行したほうが良いと思います。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 import tensorflow as tfimport numpy as npimport osfrom tensorflow import kerasfrom tensorflow.keras.datasets import cifar10from tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropout, Activation, Flattenfrom tensorflow.keras.layers import Conv2D, MaxPooling2Dimport matplotlib"Agg" )import matplotlib.pyplot as plt'GPU' )[0 ]True )32 10 15 20 'saved_models' )'keras_cifar10_trained_model.h5' print ('x_train shape:' , x_train.shape)print (x_train.shape[0 ], 'train samples' )print (x_test.shape[0 ], 'test samples' )'airplane' , 'mobile' , 'bird' , 'cat' , 'deer' ,'dog' , 'frog' , 'horse' ,'ship' , 'truck' )def to_label (v ):if idx < len (LABELS):return LABELS[idx]else :return None for i in range (0 , 40 ):5 , 8 , i+1 )8 )False )False )32 , (3 , 3 ), padding='same' ,1 :]))'relu' ))32 , (3 , 3 )))'relu' ))2 , 2 )))0.25 ))64 , (3 , 3 ), padding='same' ))'relu' ))64 , (3 , 3 )))'relu' ))2 , 2 )))0.25 ))512 ))'relu' ))0.5 ))'softmax' ))compile (loss='categorical_crossentropy' ,'adam' ,'accuracy' ])'float32' )'float32' )255 255 True )if not os.path.isdir(save_dir):print ('Saved trained model at %s ' % model_path)0 )print ('Test loss:' , scores[0 ])print ('Test accuracy:' , scores[1 ])'loss' ]'val_loss' ]len (loss)range (nb_epoch), loss, marker='.' , label='loss' )range (nb_epoch), val_loss, marker='.' , label='val_loss' )'best' , fontsize=10 )'epoch' )'loss' )
実行結果 分類対象の画像です。CIFAR-10では32x32のサイズの画像を10種類に分類します。
モデルの要約です。畳み込み層、プーリング層、ドロップアウト層、活性化層(relu)を利用した典型的なCNNになっています。最後の出力には全結合層と活性化層(SoftMax)を利用しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 Model: "sequential"
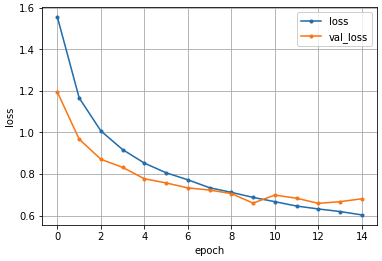
訓練経過です。だいたい1エポック9秒程度で終わっています。また検証データの正解率(val_accuracy)も77%程度になっています。ちなみに下記の結果はGPUを使用したものですが、CPUの場合は1エポックで43秒程かかりました。GPUは偉大です・・・
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Train on 50000 samples, validate on 10000 samples
損失の経過を表したグラフです。見ての通り10エポック以降から過学習をおこしています。
まとめ 本記事ではLinuxでGPUを用いた機械学習環境を構築する手順を紹介しました。特に初学者から中級者レベルの方が自宅に機械学習環境をシンプルに構築したいシチュエーションを想定して以下の環境構築を一気通貫で実施しました。
Minikube(Kubernetes)
JupyterLab
TensorFlow
Keras
CNN(Convolutional Neural Network)
今回なぜLinux+Minikube+JupyterLabの構成にしたかというと、まず機械学習の環境は依存関係が複雑な上に開発のスピードが非常に速いという問題があるからです。特にGPUのドライバのバージョンとCUDAとcuDNNとフレームワーク(TensorFlow等)のバージョンの関係は非常にセンシティブなため、コンテナとして管理した方が非常に安心してバージョンアップができます。特にMinikube(Kubernetes)で管理すれば一つ前のデプロイメントに戻すのも簡単なので環境構築の試行錯誤とノウハウの蓄積 も簡単になります。そして、本記事ではMinikubeで構築しましたが、複数マシンのKubernetesクラスタで構築すれば複数人でも利用可能な機械学習基盤になり、MLOpsにも繋がっています。
またJupyterLabはいわゆるノートブックの環境で機械学習を環境としては、試行錯誤が容易でコーディングと結果の可視化が両立されており非常に使い勝手が良いのでおすすめです。ノートブックに関しては以前に「全プログラマに捧ぐ!図解「ノートブック」 」という記事を書いたのでそちらを参照してください。
本記事は自分が一番最初にLinuxで機械学習環境を構築しようとした時に、多くの手順に苛まれてなかなかお目当てのディープラーニングまで辿り着けなくてもどかしい思いをした経験から、環境構築からディープラーニングまで一気通貫で記事を構成してみました。
駆け足での説明になってしまいましたが、機械学習に興味がある方の一助になれば幸いです。
参考文献
Minikubeを使ってローカルにkubernetes環境を構築 - Qiita tensorflow2.0 + kerasでGPUメモリの使用量を抑える方法 - Qiita Keras+CNNでCIFAR-10の画像分類 CIFAR-10のデータセットを用いてCNNの画像認識を行ってみる - AI人工知能テクノロジー
おまけ DockerfileはGitで管理しておくと便利です。また、Dockerfileのビルドからデプロイおよびコミットまで自動化しておくと間違いがありません。以下はRubyスクリプトですが自分が使っているものです。ポイントはsedでkubernetes.io/change-causeを書換えていることです。こうすることでデプロイメントを更新可能にしています。イメージのバージョンは大きな変更をした場合だけ上げるようにして、ちょっとした変更(機械学習用のライブラリ追加等)はDockerfileをちょっと修正してこのスクリプトを実行するだけで環境のアップデートが終わるので非常に楽です。
1 2 3 4 5 6 7 8 9 10 11 12 13 #!/usr/bin/env ruby $VERSION = "v1.13" "docker build -t ml/all:#{$VERSION } ." ) |raise ('Failed to docker build' )"\"modified at #{Time .now} \"" "sed -i -e 's/\\(kubernetes.io\\/change-cause: \\).*$/\\1#{msg} /' ml-deploy.yml" raise ('Failed to sed' )"kubectl apply -f ml-deploy.yml" ) |raise ('Failed to sed' )"git add ml-deploy.yml" ) |raise ('Failed to add' )"git add Dockerfile" ) |raise ('Failed to add' )"git commit -m 'modify ml/all image'" ) |raise ('Failed to commit' )