🎉🎉祝Ruby2.7リリース🎉🎉 クリスマスなのでRubyの22年に渡るコミットの歴史を可視化してみた
この記事はRuby Advent Calendar 2019の25日目の記事です。
本日はクリスマスということで、例年ならRubyの新バージョンがリリースされる日になります。
新バージョンのRuby 2.7はRC2までやってきたので、リリースに向けて着実に進んでいるようです。
🎉🎉 そして無事に本日リリースされました!! おめでとうございます!!! 🎉🎉(本記事投稿時点ではまだリリースはされていません。)
そこでRuby2.7のリリースのお祝いとコミッターのみなさんのハードワークに感謝の気持ちを込めて、Rubyの22年に渡るコミットの歴史を可視化してみたいと思います。
はじめに
一番最初の動機はコミッターのみなさんが日々どれだけのコミットを積み重ねているのかを過去から遡って見てみたいというものでした。しかしRubyの誕生は1993年と言われており、27年の開発の歴史の中で関わっているコミッターの数は200人を超えるので単純な棒グラフや線グラフでは可視化が破綻するのは目に見えていました。
そこで「Flourish」というサービスを使い、時間軸を加えた棒グラフのアニメーションを利用することで、常にトップ20のコミッターの様子を捉えられるようにします。
完成イメージは上記のようになります。上の画像を2019年までアニメーションさせるための作業を行うことが本記事の趣旨になります。また、せっかくなのでなるべくRubyを使ってこの作業を行ってみたいと思います。
それでは行ってみましょう。
コミットログを収集する
何はともあれ、コミットログを収集しないと可視化ができません。そこでRubyのリポジトリを取得することから始めたいと思います。
Rubyのリポジトリを取得する
まずはGitHubのRubyリポジトリクローンしてきます。
1 | |
ただし、上記のリポジトリのページにはタイトルに以下のように[mirror]と付いています。
The Ruby Programming Language [mirror]
これはどういうことかというと、実はRubyは正式なRubyのGitリポジトリはGitHubとは別のGitリポジトリで管理されています。また、それ以前にRubyの開発は2019年4月22日までSVNリポジトリで管理されており、一部のブランチはまだそちらで開発が続いているという事実もあります^1。
その辺の経緯は「令和時代のRubyコア開発」に書いてありました。歴史の長いプロダクトはバージョン管理システムを変えるのに大きな労力を伴うという一例だと思います。
話は逸れますがこのURLにメールアドレスが載っていないと2020年1月1日以降pushができなくなるみたいなのでコミッタの方はお気を付けください。
Rubyのリポジトリを覗いてみる
リポジトリのクローン後にやることと言えば、一番最初のコミットと一番最後のコミットを見ることだと思います。まずは最後のコミットをgit logコマンドで見てみます。
1 | |
最後のコミットは12/23に行われています。次に一番最初のコミットを見てみます。git logコマンドに--reverseオプションをつけることで先頭からコミットを見ることができます。
1 | |
一番最初のコミットは1998/1/16に行われたようです。ログにby cvs2svnとあるのでバージョン管理システムをCVSからSubversionに移行するためにcvs2svnコマンドを用いたようです。
1 | |
また、コミットログにgit-svn-idが残っているので、このリポジトリはSubversion時代にgit-svnコマンドを用いてGitHubと同期されていたことも分かります。このへんの経緯をまとめたものがないかなとネットを検索したらるびま0052号に書かれていました。Gitに移行した現在の状況も加味すると以下のようになります。
| 年代 | バージョン管理システム |
|---|---|
| 1993〜1998/1 | RCS/tarボール? |
| 1998/1〜2006/12 | CVS |
| 2006/12 〜 2019/4 | Suvbversion |
| 2019/4 〜 現在 | Git |
コミットログに残っているのはCVSで管理された1998年以降なので、可視化できるのはこの約22年間分のコミットになります。残念ながらRuby誕生から約5年間の歴史は可視化できないことをご了承ください。
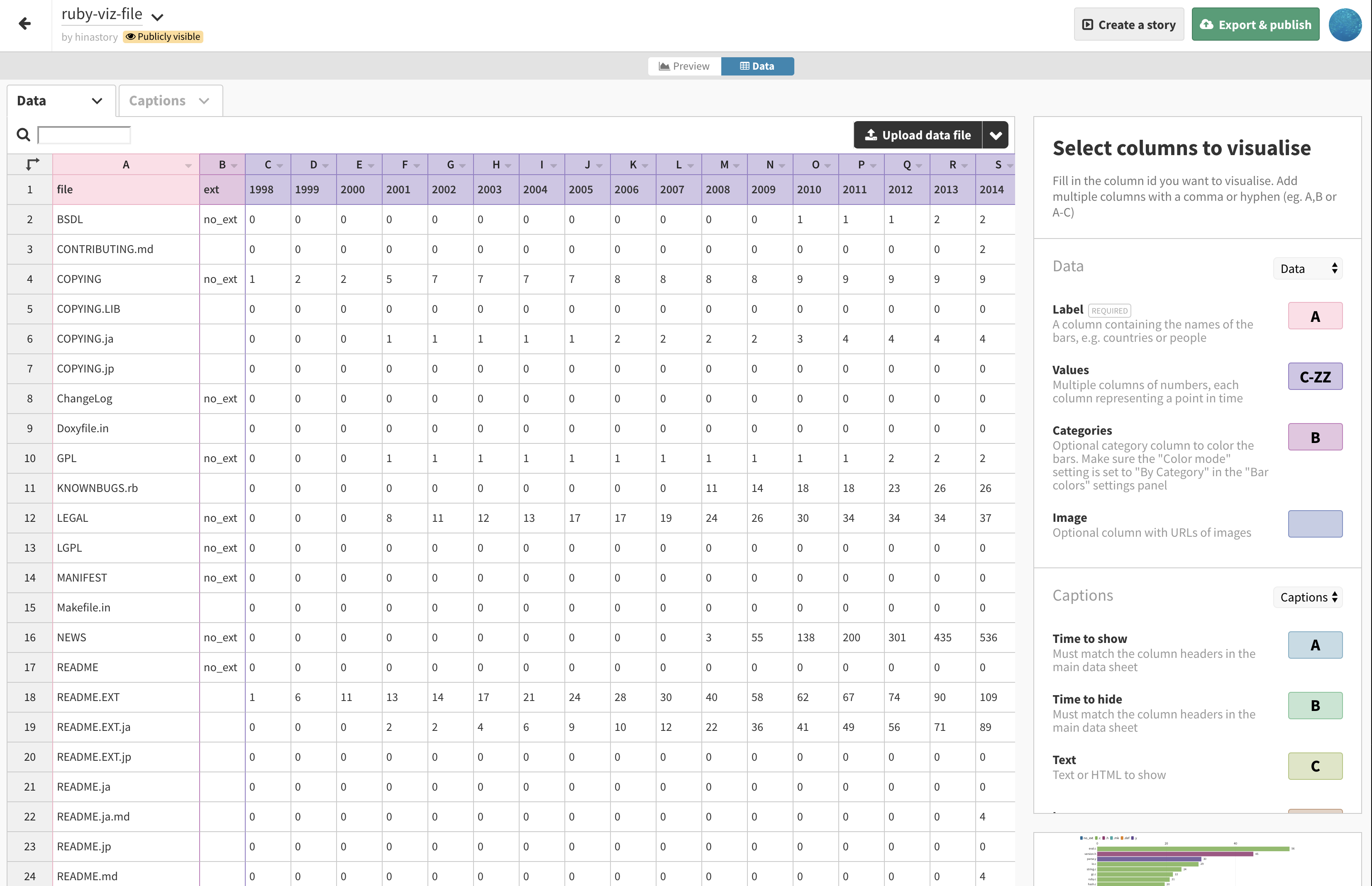
作者別にコミット数をカウントしてみる
次に年単位で作者別にコミット数をカウントしてみます。原理上はコミットログさえあればコミットの日付とコミットの作者とコミット数が分かるので、最初はコミットログを自力でパースしてカウントしようと思っていましたが、git shortlogという便利なコマンドがあることに気づきました。
以下のコマンドで1998年から2019年までの作者別のコミット数を見ることができます。
1 | |
オプションは以下のとおりです。
| オプション | 説明 |
|---|---|
-n |
作者ごとのコミット数でソート |
-s |
コミット数の概要のみ表示 |
-e |
Eメールアドレスを表示 |
--no-merges |
マージコミットを除外 |
−−since |
開始日時 |
--until |
終了日時 |
トップ10は以下のとおりです。1位はご覧の通りnobuさんで圧巻の1万6千コミット。2位にトリプルスコア以上の差をつけて圧倒的な戦闘力を誇っています。
1 | |
ただ上記のコミット数の表示には大きな問題があります。分かる人には分かると思うのですが、実は1位のnobuさんと9位のNobuyoshi Nakadaさんは同一人物です。これは作者名やEメールアドレスが異なると異なるものとしてカウントされてしまうためです。
この問題を解決するためには名寄せといって同一人物と思われるコミットを集約しないといけません。実はgit shortlogには.mailmapという集約の仕組みがあるのですが、これを利用するためにはそもそも同一人物のEメールアドレスがどれかという情報を持っている必要があります。
今回はどのEメールアドレスが同一人物かを推測するところから始めるので.mailmapの仕組みは利用せずRubyを用いて集約を頑張ってみたいと思います。
年単位でコミット数をカウントしてみる
前節で1998年から2019年までのコミット数を集計しましたが、年単位で可視化を行いためスクリプトで年ごとのコミット数のログを作成します。作成するログは2種類あって1998年からの累積のコミット数を年単位で集計するtotalログと各年のコミット数を集計するtrendログです。
以下のRubyスクリプトでは1998年から2019年までループでsystem関数でgit shortlogを呼び出してリダイレクトで各年ごとのコミット数のログファイルを作成しています。
1 | |
totalログを見れば総合的に活躍したコミッターの変化を可視化でき、trendログを可視化すればその年に活躍したコミッターを可視化することができます。
データの前処理のための基盤を整える
さて、年単位のコミット数を取得してログに出力したので次に行うべきは、データの可視化を行うFlourishが読み込めるデータ形式にログを変換することです。このような処理は一般的に「前処理」と呼ばれます。前述のリポジトリからログを抽出する処理と前処理とデータ登録の作業を合わせてETL(Extract/Transrom/Load)処理と呼ばれることも多いです。
前処理のツールとして最もよく利用されているのはExcelだと思われます。データサイエンティストの方ならJupyter NotebookとPythonの組み合わせが多いかもしれません。その他にも専用のETLツールは数多く存在します。しかし今回はなるべくRubyを使って作業を行うという趣旨なので、JupyterLab(Jupyter Notebookの後継)とRubyを利用して前処理を行ってみたいと思います。
環境構築方法を選択する
JupyterLabとRubyの環境を構築するには以下のような様々な方法があります。どれも一長一短ありますが、今回はDockerを使って構築してみます。
- ローカルに環境を構築する
- Anacondaを使って手っ取り早く構築できる
- ローカル環境が汚れる
- VM上に環境を構築する
- Anacondaを使って手っ取り早く構築できる
- ローカル環境は汚れないがOSインストールからなので手間がかかる
- コンテナを使って環境を構築する
- 既存のコンテナイメージをベースに手っ取り早く構築できる
- Docker環境の構築とDockerfileの準備が必要
- クラウド上のマネージド・サービスを利用する
- クラウド上のノートブックを使って気軽に始められる
- 環境の自由度が低い
Dockerfileの準備
以下が作成したDockerfileです。ベースにしたコンテナイメージは「14言語をぶち込んだJupyter LabのDockerイメージを作ってみた」で公開されていたベースイメージを元にRubyだけを残して、JupyterLabの設定や拡張を入れたり、必要なRubyGemsを入れたものになります。
Dockerfileのポイントは「install Ruby」のコメントで始まる一連の処理になります。ここでRubyをruby-buildでビルドして、JupyterLabからRubyを選択して起動できるようにRubyカーネルをgemでインストールしています。
1 | |
見ての通りRubyは2.6.5を利用しています。2.7.0-rc2も試してみたのですが、うまく動作しなかったので断念しました。DockerファイルはGitHubにpushしてあるのでご利用ください。

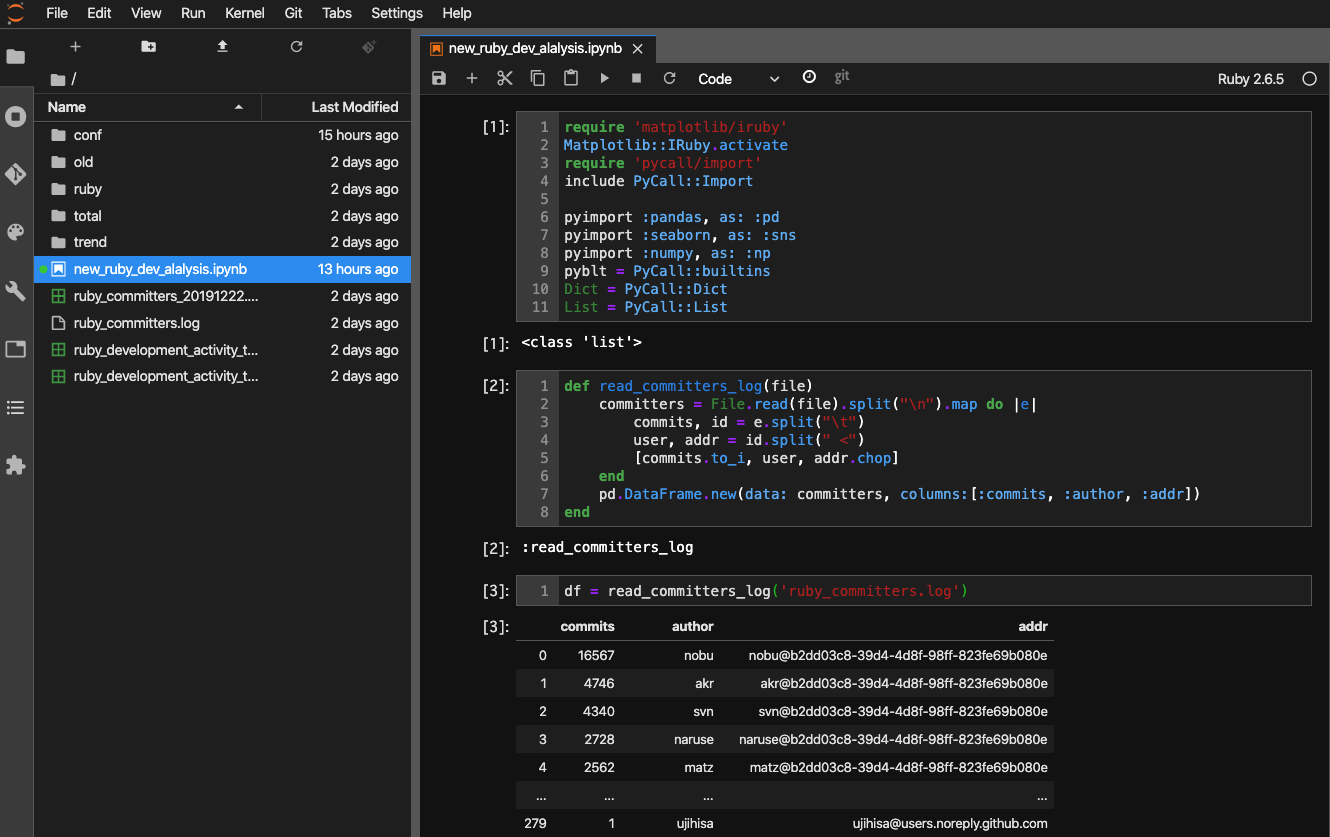
JupyterLabの起動画面
以下が実際の起動画面になります。テーマは自分の趣味でダークにしてあります。
JupyterLabとRubyでデータの前処理を行ってみる
基本的にはPyCallとpandasを用いて作業します。PyCallやRubyからPythonを呼び出せるライブラリで、pandasはPythonで主にデータフレームを扱うためのライブラリです。
データフレームを用いるとExcelのように表形式のデータが扱いやすくなります。
Rubyコミッタの名寄せを行ってみる
ここからの作業はノートブックを用いて作業しますが、ノートブックを直接表示はできないので抜粋して説明します。
まずは、ライブラリを読み込みます。またPyCallのよく使う変数はショートカットを定義しておくと便利です。以下ではPythonの組み込み関数はPyCall::builtinsに定義されているのでpybltに格納しています。
1 | |
次にコミッターログ(前述のgit shortlogで作成した1998年から2019年までの作者別コミット数)を読み込んでデータフレームを作成します。
read_committers_log関数はコミッターログをパースして、コミット数と作者とEメールアドレスに分割してデータフレームを作成しています。
1 | |
次に名寄せの戦略として作者(author)が同名のものは同一人物だと仮定してどれだけ名寄せできるか確認します。ここで284から267まで名寄せできることを確認しました。
1 | |
そして実際にauthorで名寄せを行います。以下はauthorでgroupbyしたあと、コミット数を合計し、Eメールアドレスはカンマを挟んで結合して、コミット数でソートしたあとインデックスをリセットしています。
pandasの集約関数のaggには辞書を明示的に渡す必要があります。最初はここにRubyのハッシュをそのまま渡していて動かなくて悩みました。また、PythonでLambda関数を渡す箇所にはProcオブジェクトを渡す必要がありました。RubyのLambdaでは動きませんでした。これがPyCallの仕様かどうかはあまり時間がなかったので調べられていません・・・
1 | |
作者名の次の名寄せはメールアドレスの先頭部分(@より前の部分)を用いました。この戦略は間違う確率が高い危険な方法ですが、とりあえず間違った箇所は個別に対処することにして実行しました。
以下のコードはメールアドレスの先頭部分を抜き出し、データフレームの最後にaddr_userとして追加するコードです。
試行錯誤しながら特殊な場合分けをしています。面白いのはmatzbotの存在です。このボットは毎日定期的ににversion.hのRUBY_RELEASE_DAYを書き換えるお仕事をしているようです。
1 | |
次のコードは実際にaddr_userで名寄せを行っています。作者名(author)の集約には文字列が長い方を採用しています。一般的に最初は短いユーザ名を用いていたが後から本名をauthorに設定する方が多くいたからです。
1 | |
次に名寄せしたユーザ名がGitHubに存在するか確認します。これは最終的にGitHubのユーザ名をユニークなキーにして、GitHubのアバターを可視化に用いたいからです。
1 | |
以下のコードはGitHubユーザが見つかった場合はそのまま、addr_userをそのまま出力し、そうでない場合は先頭にXXXX_を付加した文字列をtmp_userとして列に追加します。
1 | |
最後に列の並びを`reindex`で整理して一時ファイルにCSV形式で保存します。
1 | |
ここまででようやく名寄せの第一段階がおわったところです。ここまでの作業結果は以下のノートブックで確認できます。
この後は作者名をキーにしてGoogleで検索をかけてnokogiriでスクレイピングをしてGitHubユーザ名の候補を出力するようなことをして名寄せの精度を高めたりしましたが、結局最後は人力で頑張りました。
名寄せの結果は以下にコミットしたので間違っていたらイシューかプルリクでお知らせ頂けると幸いです。
最終的な集計テーブルを作成する
ようやく名寄せを行ったコミッターのマスターテーブルが完成したので、これをもとに年単位で集計したログをFlourishが読み込めるデータに変換します。
以下のコードはコミッターのマスターテーブルにコミット数に応じてコミットランクをつけています。コミットランクは以下の用になっています。
完全に自分の主観です。区切りのいいところに置いてみただけです。
| ランク | コミット数 | 説明 |
|---|---|---|
| C | 10未満 | 初級者 |
| B | 10以上100未満 | 中級者 |
| A | 100以上1000未満 | 上級者 |
| S | 1000以上10000未満 | 超人 |
| SS | 10000以上 | 神 |
1 | |
次のコードは年単位で集計したデータをマスターデータを使って集約しています。集約はマスターデータのaddr欄のメールアドレスに対象のメールアドレスが部分文字列として含まれているかどうかで判断しています。
1 | |
以下のコードは新たな列としてGitHubのユーザの場合はアバターのURLをimage列として追加し、またユーザ名と作者名を結合したlabel列を付加しています。
1 | |
次のコードで最終的なテーブルを作成しています。具体的には列として1998年から2019年までの22列を追加しています。
1 | |
ここまでの作業結果は以下のノートブックで確認できます。
また出力結果は以下のファイルになります。
Flourishで可視化してみる
Flourishは非常に多くの可視化に対応していますが、今回はBar chart raceを用いています。
データさえ出来ていれば可視化は非常に簡単で、CSVファイルをアップロードして可視化に用いる行を選択するだけです。
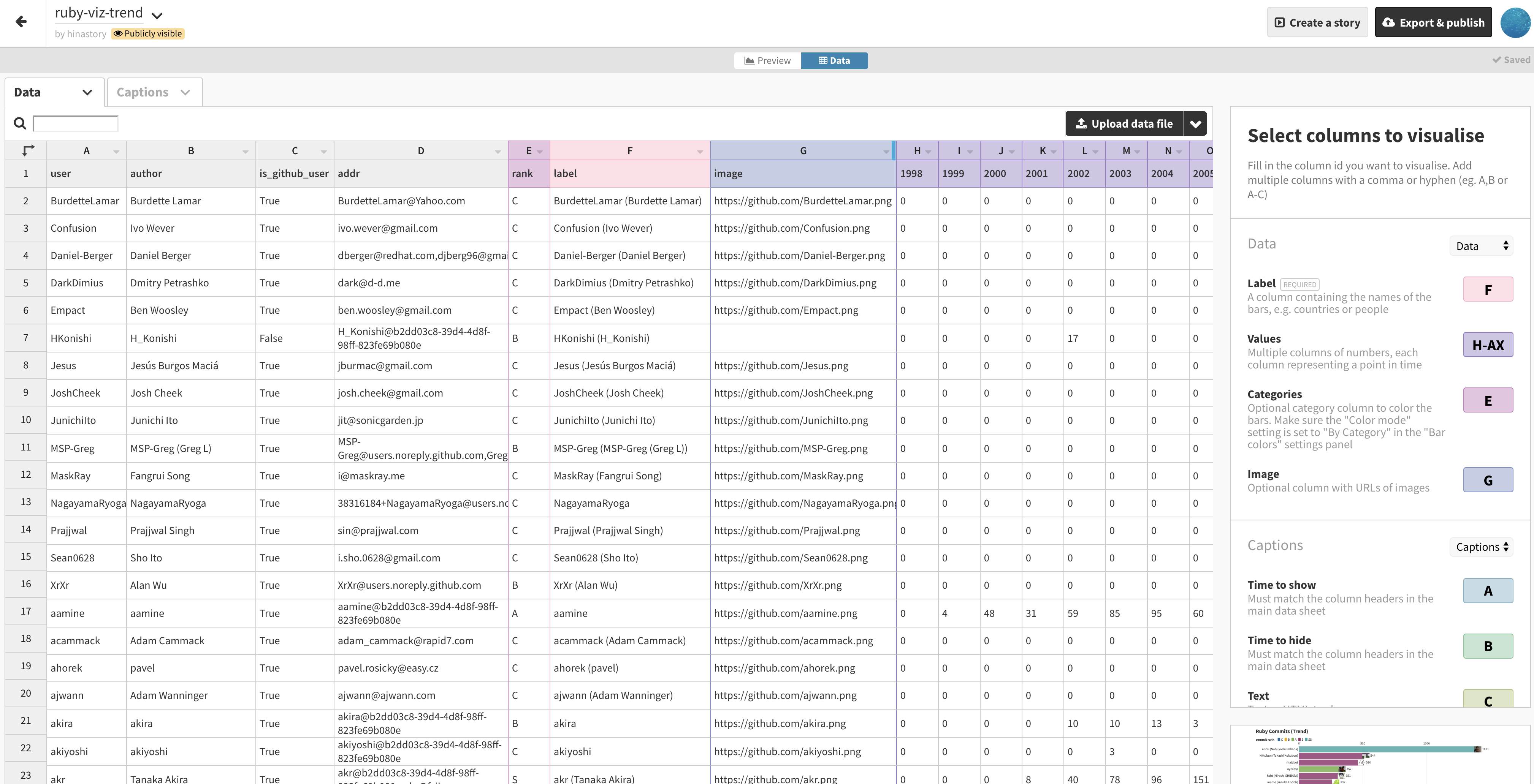
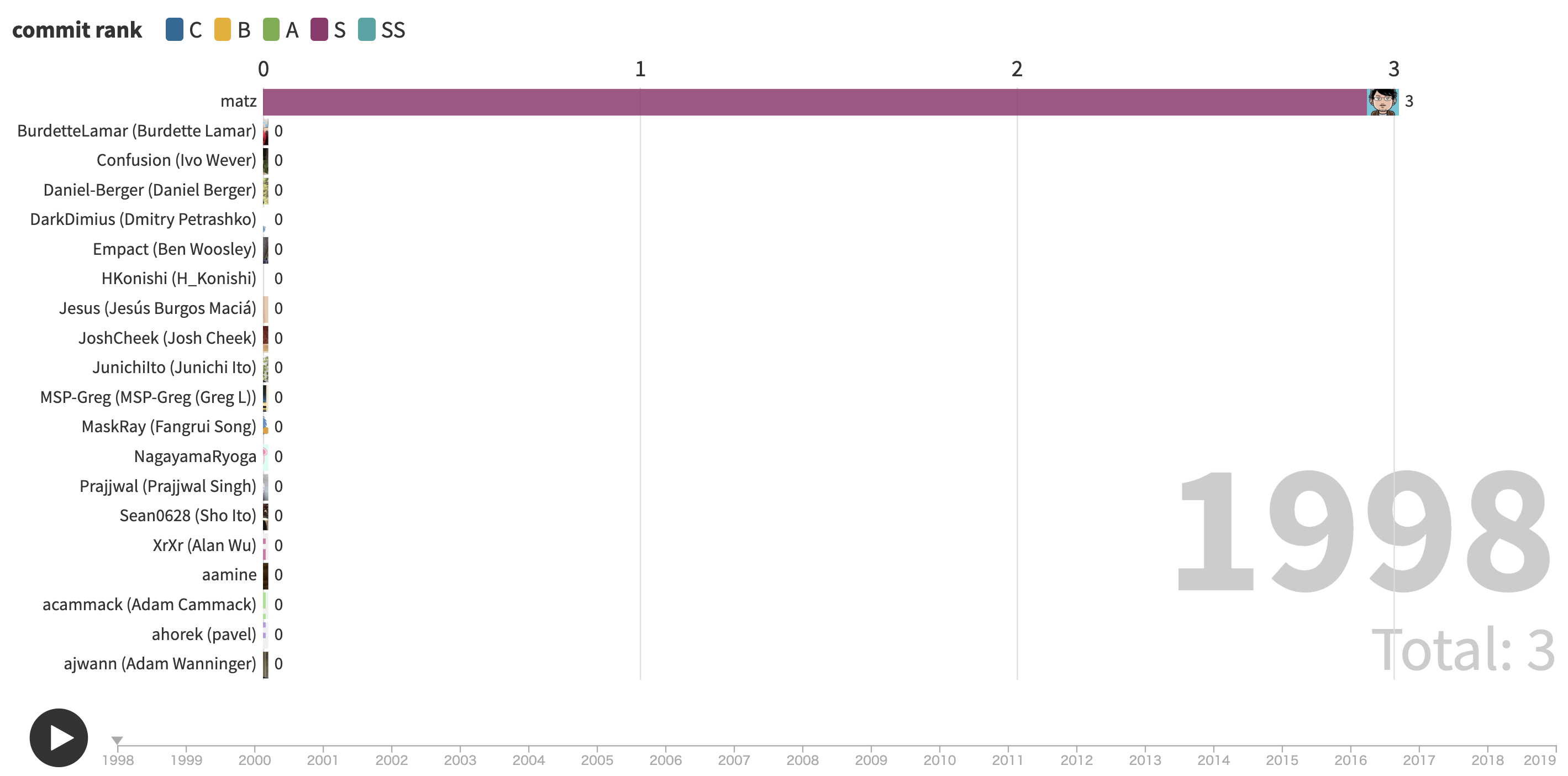
完成した可視化
以下が完成した可視化です。中央のRubyの画像はRubyホームページから引用しており、作者の画像はGitHubから引用しております^2。
以下は1998年からの累計コミット数のチャートです。
以下は年単位のコミット数の可視化です。その年に活躍したコミッターが分かると思います。
まとめ
見てのとおりコミット数1万件超えのnobuさんが圧倒的でただ一人SSランクになっています。そしてRuby作者のmatzさんは最近はRuby本体にはあまりコミットされていないようです。恐らくmrubyの開発等でご多忙なのだと思います。あと可視化に関して言えば、Ruby開発の最初の5年間はコミットログがないので可視化できていないのと、コミッターによって代理でコミットされた名もない作者が多数いると思われるので、この可視化はそういった不完全な面があることをご理解頂いた上でご覧ください。
苦労した点は多々ありますが、やはりダントツで名寄せに苦労しました。Rubyは歴史が長くコミッターの数も多いので名寄せがうまく行かないケースが多発しました。
今回GitHubのアバター画像を出す関係から最終的にはGitHubのユーザー名で名寄せを行いましたが、プロプライエタリなGitHubを嫌う方やRubyの開発から突如消えた方や大分昔にコミットが途絶えた方などでGitHubアカウントが見つけられなかった方が何人かいました。しかし苦労した分そのようなRubyの開発史を垣間見ることができたのでとても面白かったです。
本記事がRuby2.7のリリースとともに、Rubyを愛する人達へのささやかなクリスマスプレゼントになれば幸いです。
Rubyの22年に渡るコミットの歴史を可視化してみました。Rubyを愛する方たちへのクリスマスプレゼントになれば幸いです。#Ruby pic.twitter.com/wrDu6UXcTh
— hinastory (@hinastory999) December 24, 2019